
AI 연구자들이 거대하고 독점적인 모델보다 훨씬 작지만 더 우수한 성능을 보이는 새로운 오픈소스 생성 모델을 개발하는 흐름이 이번 주에도 계속되었으며, 또 한 번 놀라운 발전이 이루어졌습니다.
캐나다 몬트리올에 위치한 삼성 종합기술원(SAIT) AI Lab의 수석 AI 연구원 알렉시아 졸리쾨르-마르티노(Alexia Jolicoeur-Martineau)는 'Tiny Recursion Model(TRM)’이라는 새로운 신경망 모델을 발표했습니다. 이 모델은 내부 설정값인 매개변수가 단 700만 개에 불과하지만, 일부 까다로운 AI 추론 벤치마크에서 OpenAI의 o3-mini, Google의 Gemini 2.5 Pro 등 매개변수 규모가 1만 배 이상 큰 최신 언어 모델들과 비교할 만하거나 그 이상의 성능을 보여주었습니다.

이 연구의 목표는, 오늘날 다수의 대형 언어 모델(LLM) 챗봇을 구동하는 수조 개의 매개변수를 가진 초대형 모델을 학습하는 데 필요한 막대한 GPU 자원과 전력 투자 없이도, 탁월한 성능의 AI 모델을 저비용으로 개발할 수 있음을 입증하는 데 있습니다. 해당 연구 결과는 오픈 액세스 웹사이트 arXiv.org에 게재된 논문「Less is More: Recursive Reasoning with Tiny Networks(적을수록 더 많다: 작은 네트워크를 이용한 재귀적 추론)」에서 자세히 설명되었습니다.
졸리쾨르-마르티노 연구원은 소셜 네트워크 X(엑스)에 다음과 같이 글을 올렸습니다.
> “어려운 문제를 해결하기 위해서는 수백만 달러를 들여 대기업이 학습한 거대한 기초 모델에 의존해야 한다는 생각은 함정입니다. 현재는 LLM을 활용하는 데 지나치게 집중하고 있으며, 새로운 방향을 고안하고 확장하려는 노력이 부족합니다.”
https://x.com/jm_alexia/status/1975560628657164426
졸리쾨르-마르티노 연구원은 다음과 같이 덧붙였습니다.
> “재귀적 추론(recursive reasoning)을 적용하면, 결국 ‘적을수록 더 많다(Less is more)’는 것이 사실임이 드러납니다. 처음부터 직접 사전학습(pretraining)된 작은 모델이라도, 자기 자신에게 재귀적으로 작동하며 답변을 점진적으로 수정해 나가면, 막대한 비용 없이도 상당한 성과를 거둘 수 있습니다.”
현재 TRM의 소스 코드는 GitHub에서 공개되어 있으며, 기업 친화적이고 상업적 활용이 가능한 MIT 라이선스로 배포되고 있습니다. 이는 연구자나 기업 누구나 이 코드를 자유롭게 사용, 수정, 그리고 상용 목적을 포함한 다양한 용도로 배포할 수 있음을 의미합니다.
주의할 점 (One Big Caveat)
다만 독자들은 TRM이 특정한 유형의 문제를 해결하도록 설계되었다는 점을 인식할 필요가 있습니다. TRM은 스도쿠(Sudoku), 미로(Maze), ARC(추상적 추론 말뭉치, Abstract and Reasoning Corpus)-AGI 벤치마크에 포함된 격자 기반(grid-based) 퍼즐 및 구조화된 시각적 문제 등에서 특히 뛰어난 성능을 보이도록 만들어졌습니다.
ARC-AGI 벤치마크에는 인간에게는 비교적 쉬우나 AI 모델에게는 어려운 과제들이 포함되어 있습니다. 예를 들어, 이전에 제시된 예시 해답과 유사하지만 동일하지는 않은 기준에 따라 격자 위의 색상을 정렬하는 문제 등이 이에 해당합니다.
계층에서 단순함으로 (From Hierarchy to Simplicity)
TRM(Tiny Recursion Model)의 구조는 근본적인 단순화를 보여줍니다.
이 모델은 올해 초 소개된 계층적 추론 모델(HRM, Hierarchical Reasoning Model)을 기반으로 개발되었습니다. HRM은 작은 신경망도 스도쿠(Sudoku)나 미로(Maze)와 같은 논리 퍼즐을 해결할 수 있음을 보여준 바 있습니다.
HRM은 고주파(high-frequency)와 저주파(low-frequency)로 작동하는 두 개의 협력 네트워크에 의존하였으며, 생물학적 영감에 기반한 논리와 고정점 정리(fixed-point theorem)와 관련된 수학적 정당화를 함께 사용했습니다. 그러나 졸리쾨르-마르티노 연구원은 이러한 구조가 불필요하게 복잡하다고 판단했습니다.
TRM은 이러한 요소들을 모두 제거하였습니다. 두 개의 네트워크 대신, 자신의 예측을 재귀적으로 정제(refine)하는 단일 2층(two-layer) 모델만을 사용합니다.
모델은 임베딩된 질문과 초기 답변으로 시작하며, 이는 변수 x, y, z로 표현됩니다. 모델은 일련의 추론 단계를 거치며 내부 잠재 표현(latent representation) z를 갱신하고 답변 y를 지속적으로 정제합니다. 이 과정은 출력이 안정적인 상태에 수렴(converge)할 때까지 반복되며, 각 반복(iteration)은 이전 단계에서 발생할 수 있는 오류를 수정하여 계층적 구조나 복잡한 수학적 처리 없이도 자기개선형 추론(self-improving reasoning)을 수행하게 됩니다.
재귀가 규모를 대체하는 법 (How Recursion Replaces Scale)
TRM의 핵심 개념은 “재귀(recursion)가 깊이(depth)와 규모(size)를 대체할 수 있다” 는 점입니다.
모델은 자신의 출력을 반복적으로 추론함으로써, 메모리나 계산 비용의 증가 없이도 더 깊은 신경망 구조를 효과적으로 모방(simulate)할 수 있습니다. 이러한 재귀 순환은 최대 16단계(supervision steps)까지 수행되며, 단계가 진행될수록 점진적으로 더 나은 예측을 생성합니다. 이는 대형 언어 모델(LLM)이 여러 단계를 거쳐 사고의 흐름을 전개하는 ‘사고의 연쇄(chain-of-thought)’ 방식과 유사하지만, TRM에서는 작고 단순한 피드포워드(feed-forward) 설계로 구현되었습니다.
이러한 단순함은 효율성과 일반화 능력 모두에서 뛰어난 성과를 보입니다. TRM은 적은 층 수, 고정소수점 근사(fixed-point approximation) 미사용, 이중 네트워크 계층 구조 부재라는 세 가지 단순화 원칙을 따릅니다. 또한, 경량 중단(halting) 메커니즘을 통해 모델이 스스로 정제를 중단할 시점을 결정하여, 불필요한 계산 낭비를 막으면서 정확도를 유지합니다.
규모를 뛰어넘는 성능 (Performance That Punches Above Its Weight)
작은 규모에도 불구하고, TRM은 수백만 배 더 큰 모델들과 맞먹거나 능가하는 벤치마크 성과를 보여주었습니다.
테스트 결과는 다음과 같습니다.
• Sudoku-Extreme: 정확도 87.4% (HRM의 55% 대비 큰 향상)
• Maze-Hard 퍼즐: 정확도 85%
• ARC-AGI-1: 정확도 45%
• ARC-AGI-2: 정확도 8%
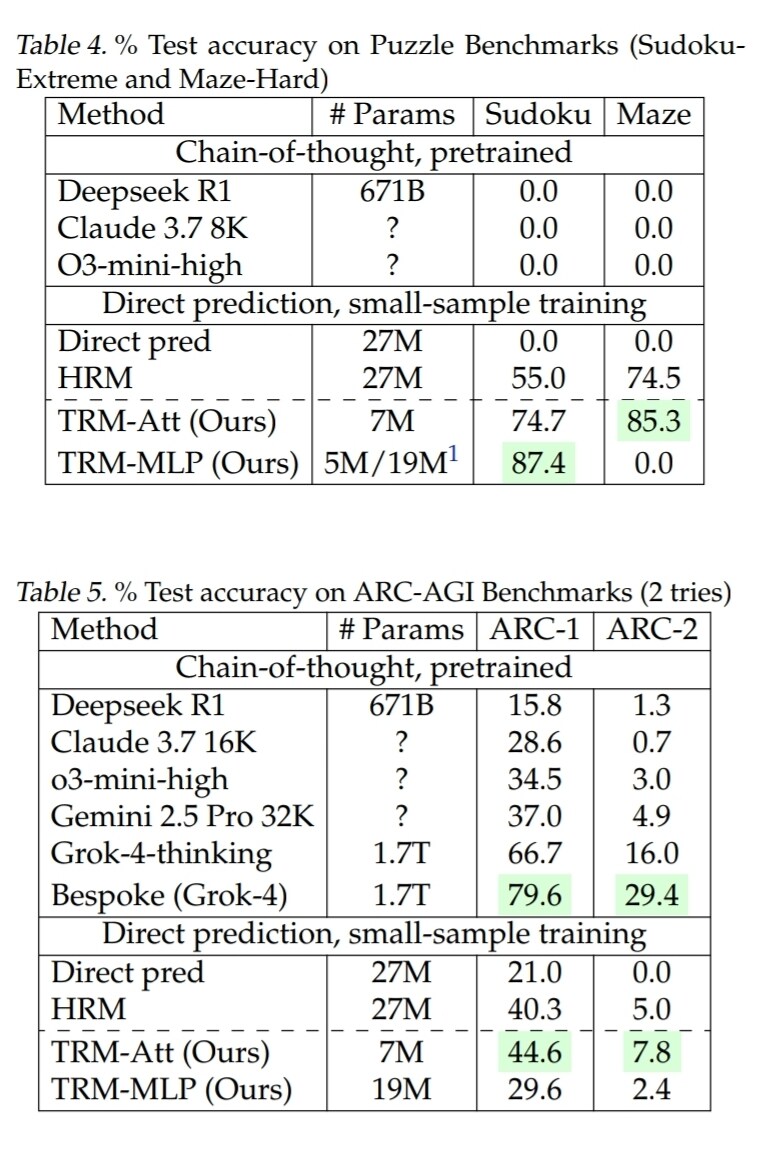
이 성과는 DeepSeek R1, Gemini 2.5 Pro, o3-mini와 같은 고성능 대형 언어 모델의 결과를 능가하거나 근접한 수준이며, TRM은 이들보다 매개변수 수가 0.01% 미만에 불과합니다.
이러한 결과는 추상적이고 조합적인(combinatorial) 추론 문제를 해결하는 데 있어 모델의 규모가 아닌 재귀적 추론(recursive reasoning)이 핵심일 수 있음을 보여줍니다. 이는 최신 생성형 모델들조차 어려움을 겪는 영역에서 특히 의미 있는 발견입니다.
설계 철학: 적을수록 더 많다 (Design Philosophy: Less Is More)
TRM의 성공은 의도적인 미니멀리즘(minimalism)에서 비롯되었습니다.
졸리쾨르-마르티노 연구원은 복잡성을 줄일수록 오히려 일반화 성능이 향상된다는 사실을 발견했습니다.
레이어 수나 모델 크기를 늘리면 작은 데이터셋에서 과적합(overfitting)이 발생하여 성능이 오히려 떨어졌습니다. 반면, 2층 구조에 재귀적 깊이와 심층 감독(deep supervision)을 결합한 설계는 최적의 결과를 달성했습니다.
또한 작고 고정된 입력 구조를 가진 작업(Sudoku 등)에서는 자기 주의(self-attention) 대신 단순한 다층 퍼셉트론(MLP)을 사용하는 것이 더 나은 성능을 보였습니다. 반면, ARC 퍼즐처럼 큰 격자(grid)에서는 자기 주의가 여전히 유용했습니다. 이러한 결과는 모델의 구조는 데이터의 형태와 규모에 맞게 설계되어야 하며, 단순히 “큰 것이 좋다”는 접근은 적절하지 않음을 시사합니다.
작게 학습하고, 크게 사고하다 (Training Small, Thinking Big)
TRM은 현재 MIT 오픈 라이선스로 GitHub에서 공개되어 있습니다.
저장소에는 전체 학습 및 평가 스크립트, 스도쿠·미로·ARC-AGI용 데이터셋 빌더, 그리고 논문에 제시된 결과를 재현할 수 있는 구성 파일(reference configuration)이 포함되어 있습니다.
또한, 계산 자원 요구사항도 명시되어 있습니다. 예를 들어, Sudoku 학습에는 단일 NVIDIA L40S GPU, ARC-AGI 실험에는 다중 H100 GPU 구성이 필요합니다.
TRM은 일반 언어 모델링이 아니라 구조화된 격자 기반 추론 작업에 특화되어 설계되었습니다. 각 벤치마크(Sudoku-Extreme, Maze-Hard, ARC-AGI)는 작고 명확히 정의된 입력–출력 격자 구조를 가지며, 이는 TRM의 재귀적 감독 메커니즘과 잘 맞아떨어집니다.
학습 과정에서는 색상 변환(color permutation), 기하학적 변형(geometric transformation) 등 데이터 증강(data augmentation)이 대규모로 사용되었으며, 이를 통해 TRM의 효율성이 매개변수의 크기에서 비롯된 것임을 강조합니다.
TRM의 단순성과 투명성 덕분에, 이 모델은 대형 연구소 밖의 연구자들에게도 접근성이 높습니다. TRM의 코드베이스는 기존 HRM 프레임워크를 기반으로 하지만, 생물학적 유추, 다중 네트워크 계층, 고정점 의존성을 제거했습니다.
그 결과, TRM은 “스케일이 전부다”라는 기존 철학에 대한 대안으로서, 작은 모델에서 재귀적 추론을 탐구하기 위한 재현 가능한 기준선(baseline)을 제시합니다.
커뮤니티 반응 (Community Reaction)
TRM과 그 오픈소스 코드 공개는 AI 연구자 및 실무자들 사이에서 즉각적인 논쟁을 불러일으켰습니다.
많은 이들이 이 업적을 찬양했지만, 그 방법론이 얼마나 광범위하게 일반화될 수 있는가에 대해서는 의견이 엇갈렸습니다.
지지자들은 TRM을 “1만 배 작지만 더 똑똑한 모델”이라 부르며, 거대 모델 대신 사고하는 아키텍처로의 진보라고 평가했습니다.
반면 비판자들은 TRM이 격자 기반 퍼즐이라는 좁은 영역에 집중되어 있으며, 실제 계산 절감 효과는 모델의 크기에서 비롯된 것일 뿐 총 연산량은 크다고 지적했습니다.
연구자 차윤민(Yunmin Cha)은 “TRM의 학습은 대규모 데이터 증강과 다중 재귀 반복에 의존하며, 결국 ‘더 많은 연산, 같은 모델’ 구조”라고 분석했습니다.
암유전학자이자 데이터 과학자인 셰이 러브데이(Chey Loveday)는 TRM이 대화형 언어 모델이 아니라 구조화된 문제 해결기(solver)라는 점을 강조하며, “TRM은 열린 언어 생성보다는 구조적 추론에서 탁월하다”고 평가했습니다.
머신러닝 연구자 세바스티안 라쉬카(Sebastian Raschka)는 TRM을 새로운 일반 인공지능 형태가 아닌 HRM의 단순화 버전으로 보았습니다. 그는 TRM의 과정을 “내부 추론 상태를 갱신하고 답변을 정제하는 두 단계 루프(two-step loop)”로 설명했습니다.
여러 연구자들, 특히 오귀스탱 나벨(Augustin Nabele) 등은 TRM의 강점이 명확한 추론 구조에 있다고 인정하면서도, 앞으로 덜 제약된 문제 유형으로의 확장 가능성이 증명되어야 한다고 말했습니다.
온라인에서 형성된 공통된 합의는 다음과 같습니다.
>“TRM의 적용 범위는 좁을 수 있으나, 그 메시지는 넓습니다. 무한한 확장보다 신중한 재귀가 다음 세대의 추론 연구를 이끌 열쇠가 될 수 있습니다.”
미래 전망 (Looking Ahead)
현재 TRM은 감독형(supervised) 추론 작업에 주로 적용되고 있으나, 그 재귀적 구조는 다양한 확장 가능성을 내포하고 있습니다. 졸리쾨르-마르티노 연구원은 하나의 결정적 답변 대신 다수의 가능한 해답을 생성하는 생성형(generative) 혹은 다중 해답(multi-answer) 변형 모델의 탐구를 제안했습니다.
또한, 재귀의 규모 법칙(scaling laws for recursion)—즉 “적을수록 더 많다(Less is more)”의 원리가 모델 복잡도나 데이터 크기가 증가할 때까지 어디까지 유효한가를 밝히는 것도 중요한 열린 연구 과제입니다.
궁극적으로, 이번 연구는 실용적인 도구이자 개념적 통찰을 동시에 제공합니다.
AI의 진보는 반드시 모델의 규모 확장에만 의존할 필요가 없습니다. 때로는 큰 모델을 한 번 생각하게 하는 것보다, 작은 모델이 깊게 반복해서 생각하도록 가르치는 것이 더 강력할 수 있습니다.
(IP보기클릭)121.175.***.***
.......
(IP보기클릭)106.101.***.***
(IP보기클릭)121.175.***.***
.......
(IP보기클릭)119.197.***.***