
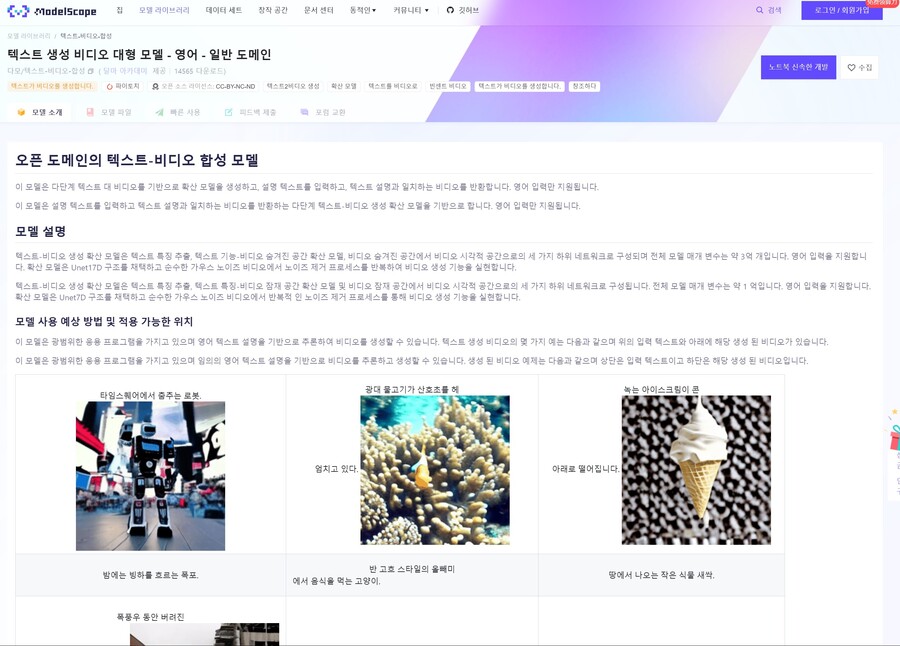
아래 링크에서 좀 느리기는 하지만 간단한 데모 버전을 사용해 볼 수 있습니다.
ModelScope Text To Video Synthesis - a Hugging Face Space by damo-vilab
Robot dancing in times square.
A cat eating food out of a owl,
in style of van Gogh.
Melting ice cream dripping
down the cone.
물론 weubi로 로컬 사용이 가능합니다.
사용법은 간단합니다.
(Automatic1111 webui 기준 : AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com))
1. 먼저 webui용 익스텐션을 설치합니다. 익스텐션 주소를 webui의 Extensions / Install from URL / URL for extension's git repository 에 붙여넣은 다음 Install을 누릅니다.
3. 이제 아래 링크로 가서 모델 및 설정 파일을 전부 다운 받습니다. 받은 파일들은 webui가 설치된 폴더의 stable-diffusion-webui/models/ModelScope/t2v/ 경로에 넣습니다. 폴더가 없으면 새로 만드시면 됩니다. 모델 파일을 넣고 webui를 재시작합니다.
모델 : damo-vilab/modelscope-damo-text-to-video-synthesis at main (huggingface.co)
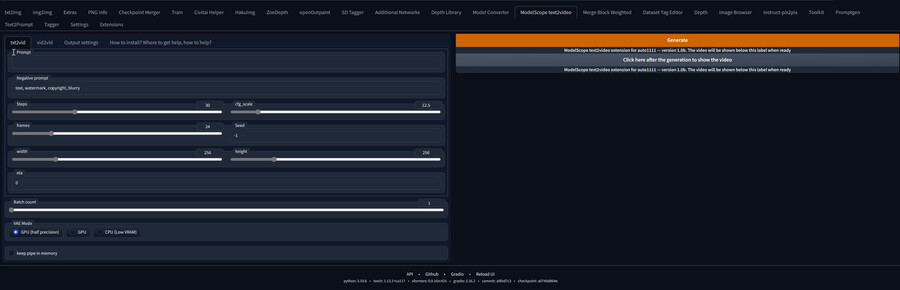
4. 각 항목의 의미는 다음과 같습니다.
-txt2vid 텍스트에서 비디오를 생성합니다.
-prompt : 일반적인 프롬프트 입니다. 현재 모델이 기본 stable diffusion 베이스라 SD용 프롬프트를 입력하시면 됩니다.,
-Negative prompt : 마찬가지로 네거티브 프롬프트입니다.
-Steps : 이미지 생성에 사용되는 스텝과 동일합니다. 올릴수록 디테일이 올라가지만 오래 걸립니다.
-CFG_scale : 이미지 생성에 사용하는 것과 동일합니다. 높을수록 프롬프트에 충실한 이미지가 생성되지만 지나치면 이미지가 왜곡됩니다.
-frames : 생성될 영상의 프레임 숫자를 결정합니다. 해당 값만큼의 이미지가 생성됩니다. 너무 높으면 vram 부족으로 터질 수 있습니다. 적당히 조정합니다.
-Seed : 이미지 생성에 사용하는 시드와 동일합니다. -1면 매번 랜덤한 값이 사용됩니다.
-width/height : 생성될 영상의 해상도를 결정합니다. 이 모델은 vram 사용량이 매우 높으며, vram 4gb의 그래픽카드는 최대 192x192 해상도의 영상을 생성할 수 있습니다. 참고 : Add minimal requirements — launching on 4 GBs of VRAM · deforum-art/sd-webui-modelscope-text2video · Discussion #27 (github.com)
-eta : 노이즈에 영향을 주는 설정입니다. 기본 값을 사용하시면 됩니다.
-Batch count : 한번에 생성할 영상의 숫자를 결정합니다.
VAE Mode : 최적화 관련 옵션입니다. 대부분 GPU(half precision을 사용하면 무난합니다. 그래도 부족하면 CPU 옵션을 사용할 수 있습니다.
-keep pipe in memory : 비디오를 생성하고나서 모델 등을 언로드하지 않고 유지합니다. 연속으로 비디오를 생성할 때 좀 더 빨라집니다.
-Generate : 영상 생성을 시작하는 버튼입니다.
-update. the video : 영상 생성이 끝나고 누르면 영상을 재생할 수 있습니다.
이제 프롬프트를 입력해서 비디오를 생성해 봅시다,
먼저 256x256 해상도로 하늘을 날고 있는 돌고래의 영상을 생성합니다.
높은 일관성을 유지하면서 프롬프트에 충실한 영상이 생성되었습니다.
생성된 영상과 프레임들은 img2img-images\text2video-modelscope 경로에 저장됩니다.
해당 모델은 서터스톡 라이브러리로 학습되었는지 Shutter stock 워터마크가 생성되는 경우가 꽤 많습니다. 네거티브 프롬프트를 잘 조정하거나 영상 편집 프로그램에서 워터마크를 제거할 필요가 있습니다.
이제 금색 돌고래가 길거리를 걷고 있는 영상을 생성합니다.
금색 돌고래가 열심히 도로를 달리는 영상이 생성됩니다.
이제는 사람을 생성해봅시다.
해상도가 낮아서 얼굴이 뭉게지기는 했지만 잘 생성됩니다.
얼굴 클로즈업 영상을 생성합니다.
눈이 좀 호러틱하기는 하지만 나름 잘 나왔습니다.
일반적인 Stable diffusion 모델과 마찬가지로 유명인들은 프롬프트에 입력하기만 해도 생성이 가능합니다.
헤엄치고 있는 일론 머스크
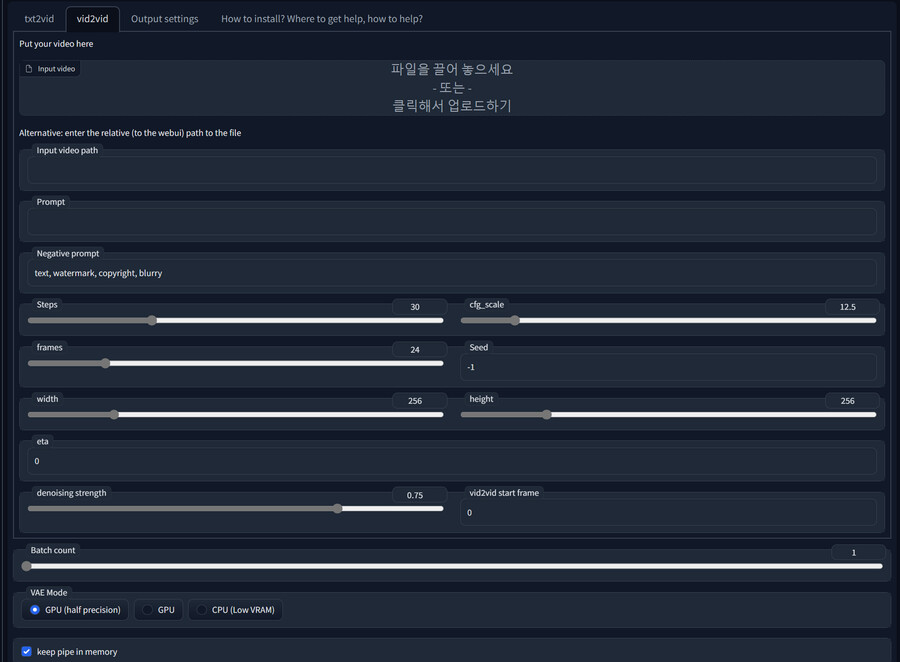
텍스트만이 아니라 img2img처럼 기존 영상에서 새로운 영상을 만드는 vid2vid도 가능합니다.
vid2vid 탭으로 이동합니다.
영상을 업로드할 수 있는 항목이 생긴 것을 제외하면 나머지는 txt2vid와 거의 동일합니다.
-Input video : 영상 파일을 업로드합니다.
-Input video path : 비디오를 업로드하는 대신 경로를 입력합니다.
-denoising strength : 원본 영상에서 얼마나 변형될지를 결정합니다. 너무 낮으면 오히려 노이즈가 증가합니다.
-vid2ivd start frame : 입력된 영상의 지정된 프레임부터 처리를 시작합니다. 앞부분을 생략할 때 유용합니다.
원본 영상을 업로드합니다. 해상도를 처리하기 좋게 편집할 필요가 있습니다.
디노이징 스트렝스 0.65를 사용합니다. SD가 베이스다보니 실사풍으로 나옵니다.
다음은 반대로 실사풍 영상을 2D로 변환해 봅시다.
디노이징 스트렝스를 0.7로 올렸더니 입이 안 움직이기는 하지만 꽤 2D풍으로 변했습니다.
터미네이터의 한 장면으로 바꿔봅시다.
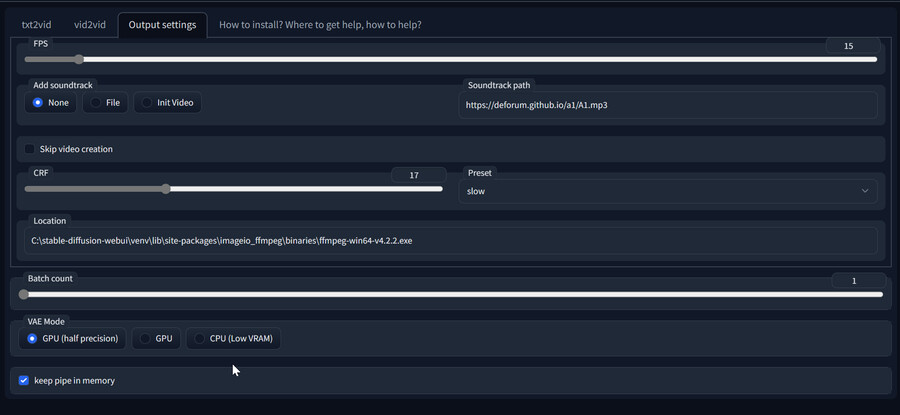
저장되는 영상은 Output settings에서 조정할 수 있습니다.
-FPS : 생성된 영상의 초당 프레임 숫자를 지정합니다. 기본값은 15입니다.
-Add soundtrack : 생성된 영상에 사운드를 삽입합니다. None : 안 넣음, File : 지정된 경로의 파일에서 가져옴, Init Video : VId2VId 사용시 입력된 영상의 사운드를 사용.
-Soundtrack Path : 위에서 File을 사용했을 경우 넣을 사운드 파일의 경로를 입력합니다.
아래와 같이 사운드가 자동으로 삽입됩니다.
-Skip video creation : 프레임 이미지들을 생성한 다음 영상으로 합치는 과정을 생략합니다.
-CRF : 인코딩 품질 옵션입니다. 높을수록 품질이 낮아집니다. 17이 기본값입니다.
-Preset : 인코딩 처리 속도입니다. 느릴수록 품질이 올라갑니다만 원체 화질이 낮아서 별 차이는 없습니다.
이외에도 오픈소스는 아니지만 비슷한 txt2vid AI 도구의 베타테스트가 진행 중입니다.
해상도나 품질은 훨씬 좋습니다.
(IP보기클릭)14.5.***.***
(IP보기클릭)211.52.***.***
(IP보기클릭)180.70.***.***
(IP보기클릭)121.162.***.***
본문에 설명한 것처럼 최소 vram 4gb가 필요합니다, | 23.03.27 00:05 | | |
(IP보기클릭)119.192.***.***
생각보다 낮네 | 23.03.30 11:58 | | |
(IP보기클릭)121.176.***.***
(IP보기클릭)59.10.***.***
(IP보기클릭)1.237.***.***
(IP보기클릭)121.162.***.***
본문에 소개한 비디오 모델은 일반 스테이블 디퓨전과 동일한 형식의 프롬프트를 필요로 합니다. "art by shinkai makoto"나 "by ufotable", "illustration" 같은 태그들을 같이 입력하시면 도움이 됩니다. 다만 기본 SD 자체가 애니메이션 스타일에는 적합하지 않은 편이라 한계가 있습니다. | 23.04.25 15:09 | | |
(IP보기클릭)1.237.***.***
아, model은 의미가 없나보군요! 감사합니다 큰 도움 되었습니다~! | 23.04.25 15:35 | | |