

PixPix 모델의 경우 잘 작동할 때는 정말 편리하지만 문제는 프롬프트만으로 이미지를 조정하다보니 결과물이 제멋대로 수정되어 생각보다 조정이 어려운 한계가 있습니다. 특히 실사 이미지가 아닌 2D 일러스트는 생각보다 제대로 인식하지 못 하는 경우가 많습니다.

이번에 새로 소개할 모델은 ControlNet(Adding Conditional Control to Text-to-Image Diffusion Models) 모델로, 다양한 알고리즘을 통해 AI에게 생성할 이미지를 지시하는 기능을 가지고 있습니다.
출처 : lllyasviel/ControlNet: Let us control diffusion models (github.com)

사용법은 간단합니다.
1. 먼저 GIt을 설치합니다.
GIt : Git - Downloading Package (git-scm.com)
2. 미니콘다를 설치합니다.
미니콘다 설치법 : 미니콘다(miniconda3) 설치 및 가상환경 생성방법 (velog.io)
3. cmd를 실행하고 아래 텍스트를 타이핑하고 엔터를 눌러 실행합니다.(아까 설치한 미니콘다로 하셔도 무방합니다)
깃헙에서 소스코드를 다운받는 과정입니다.
git clone https://github.com/lllyasviel/ControlNet
4. 아까 설치한 Anaconda Prompt (Miniconda3)를 실행하고 아까 git pull로 생성된 폴더의 경로로 이동합니다.
일반적으로 C:\Users\사용자이름\ControlNet 경로에 있습니다.
5. conda env create -f environment.yaml 를 입력하고 엔터를 눌러서 필요 모듈을 설치합니다.
6. 설치가 끝나면 conda activate control 를 입력하고 엔터를 눌러서 가상환경이 제대로 활성화되는지 확인합니다.
7. 일단 미니콘다를 종료합니다.
8. 아래 링크에서 필요한 모델 파일을 전부 다운 받습니다. 용량이 꽤 크니 주의하시기 바랍니다.
https://huggingface.co/lllyasviel/ControlNet/tree/main
하나씩 다운받으시기 귀찮으시면 cmd에 아래 텍스트를 입력해서 아까처럼 Git clone을 사용하시면 편리합니다. 아까 복사한 것과 같은 경로에 다운 받으면 이름이 동일해서 충돌할 수 있으니 다른 경로에 받으시기 바랍니다.
git clone https://huggingface.co/lllyasviel/ControlNet
8. 다운 받은 파일들을 각각 정해진 경로에 넣습니다.
다운 받은 모델 파일 중 ControlNet\models 경로에 있는 ,pth 파일을 전부 아까 앞에서 설치한 ControlNet\models 폴더에 전부 넣습니다.
다운 받은 모델 파일 중 ControlNet\annotator\ckpts 경로에 있는 파일들을 전부 아까 앞에 설치한 ControlNet\annotator\ckpts 폴더에 전부 넣습니다.
9. 사용 준비가 끝났습니다. 6번에서 했던 가상환경 활성화를 다시 해줍니다.
미니콘다에서 conda activate control 를 먼저 입력하고 앞에서 설치한 ControlNet 폴더로 이동합니다.
10. python gradio_canny2image.py 를 입력해서 오류 메시지가 출력되지 않는지 확인합니다.
Webui처럼 Running on local URL: 라는 텍스트가 출력되면 정상입니다.
이제 웹브라우저 주소창에 http://127.0.0.1:7860를 입력합니다.
아래와 같은 창이 실행되면 설치 완료입니다.
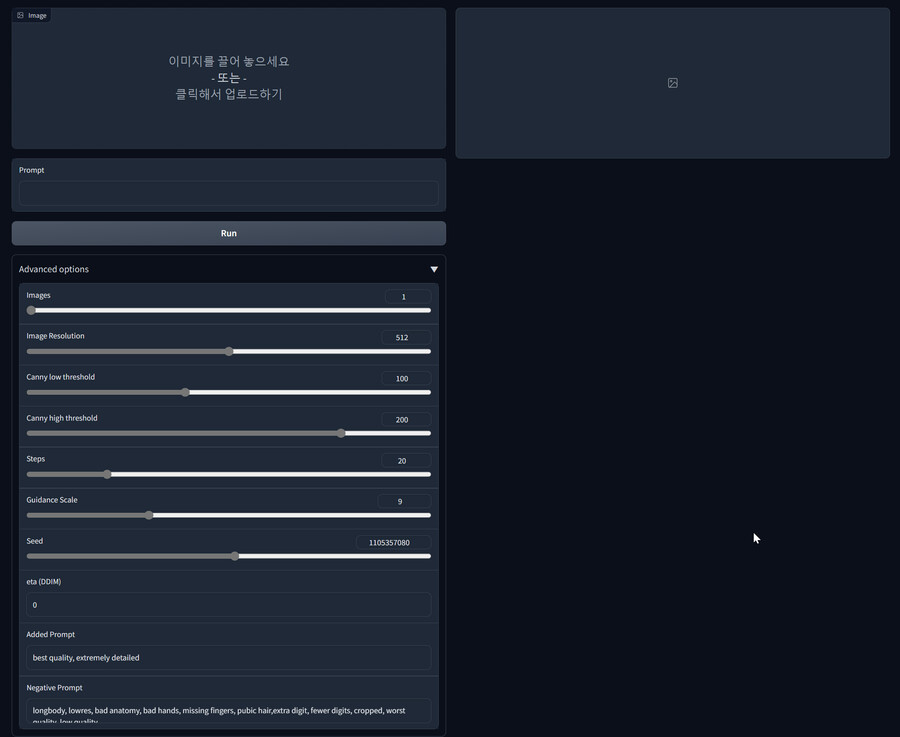
사용법은 Webui와 동일합니다.
-Image : 입력할 이미지를 넣습니다.
-Prompt : 생성할 이미지를 지시하는 텍스트입니다.
-Run : 실행 버튼입니다.
-Images : 한번에 생성할 이미지 숫자를 지정합니다. Vram 소모량도 늘어나니 적당히 조정하시기 바랍니다.
-Image Resolution : 생성할 이미지의 해상도를 지정합니다. 입력한 이미지 대비 가로 해상도만 지정합니다. 속도가 느린편이니 512가 무난합니다.
-Steps : 이미지 생성 스텝 수를 지정합니다. 올릴 수록 디테일해지지만 느려집니다.
-Gudnace Scale : 생성될 이미지가 텍스트에 얼마나 충실한지 결정합니다.
-Seed : 이미지 생성의 베이스가 되는 랜덤 노이즈 값입니다.
-Added Prompt : Prompt에 더해서 같이 입력되는 프롬프트입니다. masterpiece 같은 퀄리티 태그를 넣으면 좋습니다.
-Negative Prompt : 생성을 막을 것을 지시하는 프롬프트입니다. 마찬가지로 퀄리티 태그가 들어갑니다.
-나머지 : 각 모델들의 기능을 조정하는 값들입니다. 적당히 조정해보시면서 자신에게 맞는 설정을 찾으시는 것을 추천합니다.
-주의-
ControlNet은 아직 최적화가 덜 되서 Vram을 매우 많이 소모합니다.
사양이 중간 정도이신 분들은 속도가 좀 느려지지만 최적화를 위해서 아래 설정을 하시는 것을 권장합니다.
1. 설치한 ControlNet 폴더에 있는 config.py 파일을 메모장으로 엽니다.
2. save_memory = False를 save_memory = True로 변경합니다.
3. 저장합니다.
ControlNet은 매우 다양한 종류의 모델들을 제공하며, 각각의 모델을 실행하기 위한 스크립트가 별도로 마련되어 있습니다.
아까 python gradio_canny2image.py로 실행한 것처럼 python 다음에 아래 스크립트 중 하나를 선택해서 실행하시면 됩니다.
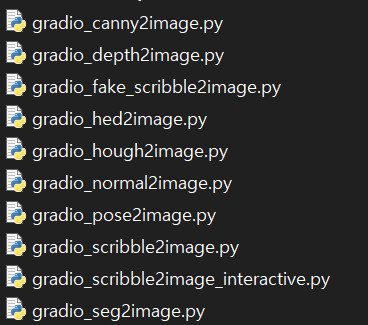
이제 각각의 모델들이 어떠한 기능을 하는지 간략하게 알아보겠습니다.
1. canny2Image
입력된 이미지의 윤곽선을 분석하고 그것을 기반으로 이미지를 생성합니다.
1 : 입력 이미지 / 2 : 분석한 윤곽선 / 3 : 2를 참고해서 생성된 이미지.

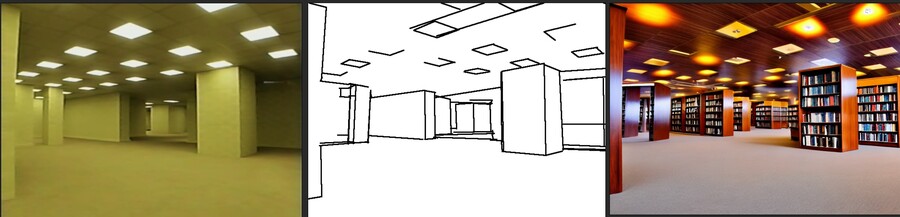
2. hough2image
1과 비슷하지만 대신 직선만을 분석해서 그것을 기반으로 이미지를 생성합니다. 건물 이미지 생성에 유용합니다.
1 : 입력한 이미지 / 2 : 1을 분석한 직선 / 3 : 2를 기반으로 생성된 도서관 이미지
3. hed2image
이미지의 부드러운 윤곽을 분석해서 그것을 기반으로 이미지를 생성합니다. 1보다 원본 이미지의 디테일을 더 많이 남깁니다.
1 : 입력한 이미지 / 2 : 1을 분석한 윤곽선 / 3 : 2를 기반으로 생성된 청동상 이미지

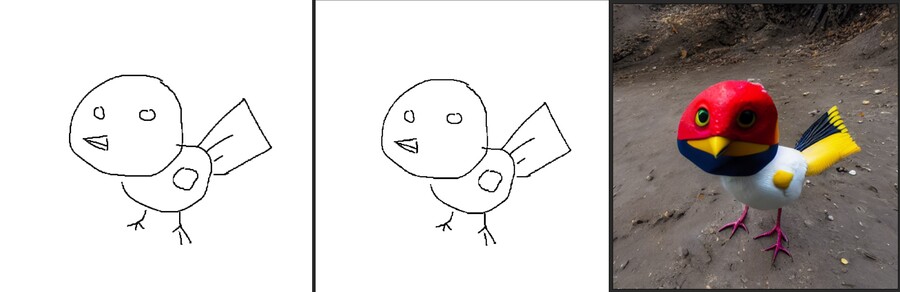
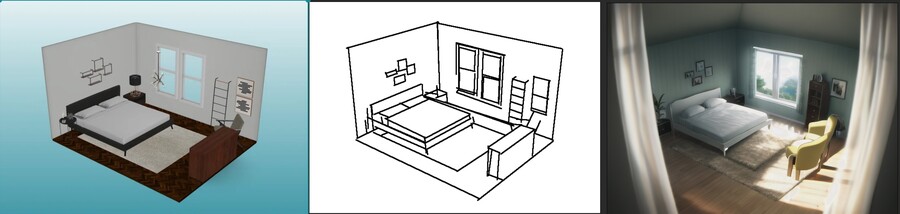
4. scribble2image
대충 그린 그림을 베이스로 이미지를 생성합니다.
말그대로 대충 그린 그림으로 이미지를 생성하는데 특화되어 있으며, 입력한 그림의 형태를 최대한 유지합니다.
검정색 선이 필요합니다.
1 : 입력한 이미지 / 2 : 1을 분석한 이미지 / 3 ; 2를 기반으로 생성된 새 이미지
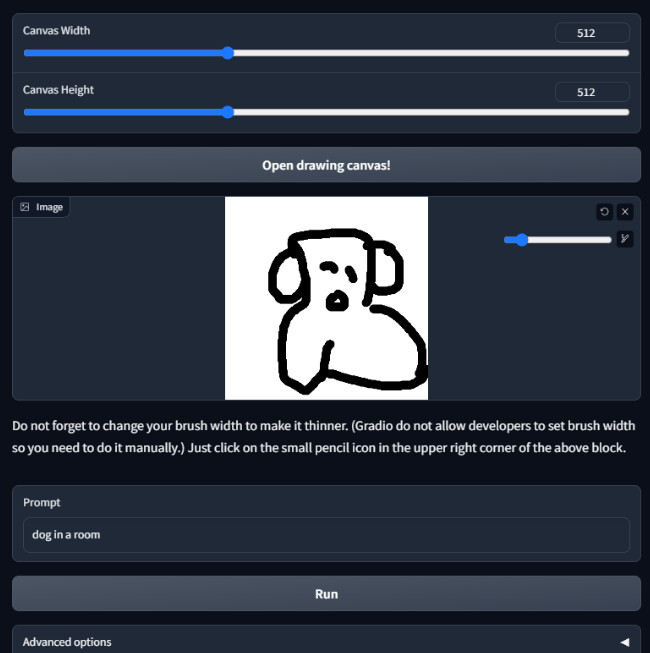
5. scribble2image_interactive
4와 동일하지만 대신 입력한 이미지를 직접 그릴 수 있습니다.
다만 너무 크기가 작아서 사용하기 힘드니 그냥 4를 사용하시는 것을 추천합니다.
6. fake_scribble2image
4와 동일하지만 대신 일반 이미지를 입력하면 분석해서 러프한 선을 만들고 그것을 참고해서 이미지를 생성합니다.
낙서도 귀찮으실 때 사용하시면 됩니다.
1 : 입력한 이미지 / 2 : 1을 분석해서 생성된 러프 / 3 : 2를 기반으로 생성된 이미지

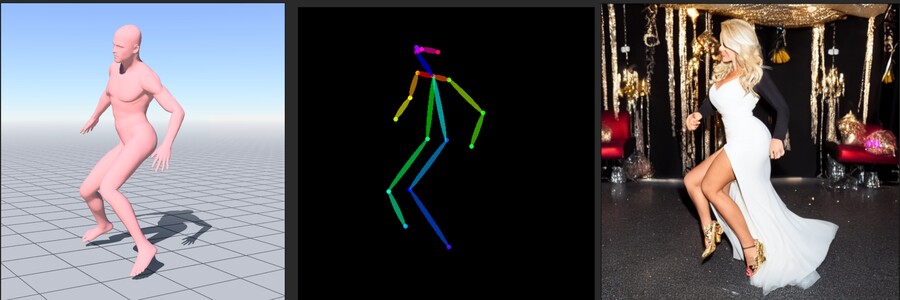
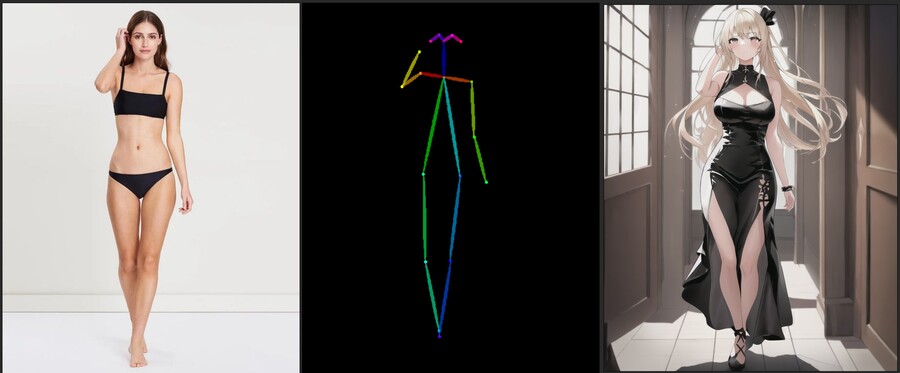
7. pose2image
입력한 이미지를 분석해서 포즈를 인식한 다음 그것을 기반으로 이미지를 생성합니다.
개발자의 코멘트에 따르면 직접 포즈를 조정할 수 있어야 히지만 UI의 한계로 이미지 인식으로 대체했다고 합니다.
실제 사람의 이미지를 넣어야 인식이 잘 됩니다.
뎁스 모델과 다른 점은 실제 포즈만을 인식해서 사용하기에 부피나 체형을 간단하게 바꿀 수 있습니다.
1. 입력한 이미지 / 2 ; 1을 분석한 포즈 / 3 : 2를 참고해서 생성된 소녀 이미지
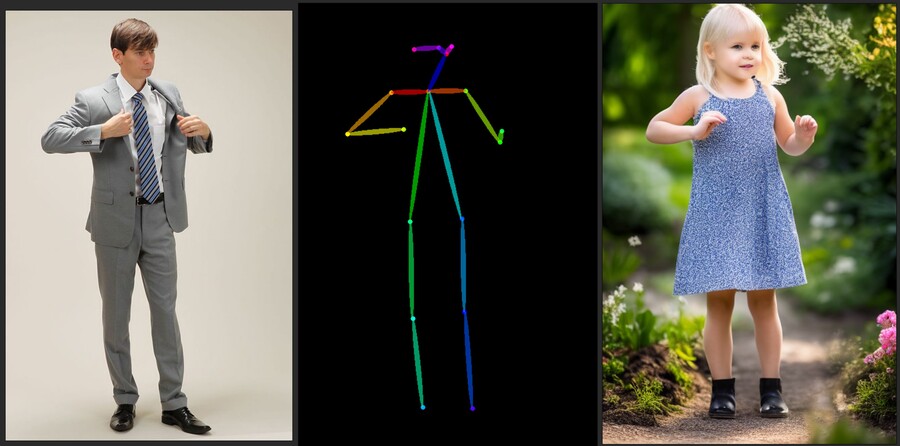
8. seg2image
입력한 이미지를 분석해서 각 영역들을 구분해서 이미지를 생성합니다.
개발자의 코멘트에 따르면 원래는 직접 칠해서 입력해야 하지만 UI의 한계로 이미지 인식을 사용한다고 합니다.
1 ; 입력한 이미지 / 2 : 1을 분석한 영역 이미지 / 3 : 2를 참고해서 생성된 물고기와 싸우는 여성

9. depth2image
저번에 소개했던 뎁스 모델과 동일합니다.
다른 점은 계산 과정에서 64x64 해상도의 뎁스맵을 사용하는 SD 뎁스모델과 다르게 512x512 해상도를 사용하기 때문 더 디테일을 유지하는 것이 가능합니다.
아래 이미지를 보시면 옷의 주름까지 남아있는 것을 보실 수 있습니다.
1 : 입력한 사진 / 2 : 1을 분석한 뎁스맵 / 3 : 2를 참고해서 생성된 이미지.

10. normal2image
입력한 이미지를 분석해서 노멀맵 (RGB로 표면의 각도값을 저장하는 텍스쳐)를 생성하고 그것을 기반으로 이미지를 생성합니다.
전체적인 덩어리만 인식하는 뎁스모델에 비해 표면의 요철까지 인식하기 때문에 더 디테일한 질감 유지가 가능합니다.
아래 이미지를 보시면 뎁스 모델과 비교해서 안경과 옷 표면의 주름까지 남아있는 것을 확인하실 수 있습니다.
1 : 입력한 이미지 / 2 : 1을 분석해서 생성된 노멀맵 / 3 : 2를 참고해서 생성된 이미지.

그리고 원래는 마지막으로 ControlNet with Anime Line Drawing 모델이 있어야 하는데 개발자가 아직 공개하지 않았습니다.
선화를 입력하면 채색을 해주는 기능을 합니다.

그런데 ControlNet 모델은 SD 1.5를 베이스로 하기 때문에 실사 이미지만 잘 생성한다는 문제가 있습니다.
애초에 이 튜토리얼 시리즈는 2D 모에풍 일러스트가 목적이기 때문에 여기서 만족할 수 없습니다.
ControlNet 모델의 개발자는 다행히도 이런 사용자들의 요구를 받아들여서 다른 모델과 병합할 수 있도록 스크립트를 업데이트했습니다.
사용법은 간단합니다.
기본적인 원리는 12편에서 소개했던 인페인팅 모델 병합과 동일합니다.
ControlNet 모델 + 병합할 모델 – SD_1.5
이번에는 먼저 Anything 3.0을 병합해보겠습니다.
어디까지나 예시이기 때문에 각자 원하시는 다른 모델을 사용하셔도 무방합니다. 2.0 모델은 불가합니다.
1 . SD 1.5 모델이 필요합니다. v1-5-pruned.ckpt을 아래 링크에서 다운받으시면 됩니다.
Anything 3.0 : runwayml/stable-diffusion-v1-5 at main (huggingface.co)
SD 1.5 : runwayml/stable-diffusion-v1-5 at main (huggingface.co)
2. ControlNet 폴더에 있는 tool_transfer_control.py 파일을 메모장으로 엽니다.
아래 부분의 텍스트를 수정합니다.
path_sd15 = './models/v1-5-pruned.ckpt'
path_sd15_with_control = './models/control_sd15_openpose.pth'
path_input = './models/anything-v3-full.safetensors'
path_output = './models/control_any3_openpose.pth'
-path_sd15 : SD 1.5 파일의 경로
-path_sd15_with_control : 병합할 ControlNet 모델 파일의 경로
-path_input : 병합할 일반 모델의 파일의 경로
-path_output : 병합이 끝난 모델 파일이 저장될 경로
3. 병합이 끝나면 기본 스크립트 기준으로 models 폴더에 control_any3_openpose.pth이 생성됩니다.
4. 이제 각 모델 파일을 실행하는 스크립트를 수정합니다.
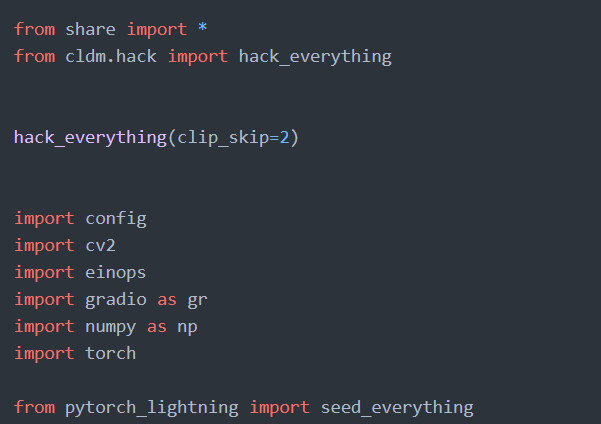
먼저 gradio_pose2image.py 파일을 메모장으로 엽니다.
import config 줄 위에 아래 텍스트를 추가합니다.
hack_everything(clip_skip=2)
from cldm.hack import hack_everything
아래 이미지 같이 하시면 됩니다.
실수로 다른 것을 지우시면 실행이 안 될 수 있으니 백업을 해두시기 바랍니다.
다른 스크립트들의 수정법도 동일합니다.
5. 그리고 model.load_state_dict(load_state_dict('./models/control_sd15_openpose.pth', location='cpu')) 에서
'./models/control_sd15_openpose.pth' 부분을 아까 병합한 모델의 경로로 변경합니다.
예를 들면 model.load_state_dict(load_state_dict('./models/control_any3_openpose.pth', location='cpu')) 이 됩니다.
이제 스크립트를 저장하고 다시 실행하시면 됩니다.
다만 ControlNet은 아직 Vram을 많이 소모하고 비교적 느리기 때문에 512 해상도 이상은 생성하지 않으시는 것이 좋습니다.
대신 뎁스 모델과 Pix2Pix 모델과 마찬가지로 Webui로 가져와서 Img2Img를 사용한 디테일업 작업을 하면 고해상도의 이미지를 얻을 수 있습니다.
저사양 컴퓨터의 경우 메모리 부족으로 꺼질 수도 있으니 주의하시기 바랍니다.
이제 병합한 모델들로 이미지를 생성하면 아래와 같습니다.
























참고로 hed2image 모델의 경우 원본을 최대한 유지하면서 이미지를 생성하기 때문에 간단하게 색이나 느낌만 변경하는데 유용합니다.
1 : 입력한 이미지 / 2 : 1을 분석한 윤곽선 / 3, 4 배경및 머리, 수영복 색, 눈색을 변경.



canny2image 모델의 경우 미세한 윤곽선을 유지하는 특성 덕분에 일종의 자동 채색 도구로도 사용이 가능합니다.
채색 전문 모델이 공개되기 전까지 사용하시면 좋을 듯 합니다.


(IP보기클릭)118.40.***.***
이 수많은 공부가 오직 성욕해소를 위해서 쓰인다는점이 나를 흥분시킵니다
(IP보기클릭)58.143.***.***
아무리 봐도 대학원생 와드
(IP보기클릭)210.92.***.***
와...
(IP보기클릭)1.244.***.***
AI도 제대로 하려면 기술자급이 되야되네
(IP보기클릭)221.153.***.***
읽진 않았지만 와드...
(IP보기클릭)222.239.***.***
https://archive.md/Aj5ZQ 님의 개쩌는 글 박제했습니다 그저 감탄만 나오는군요
(IP보기클릭)115.140.***.***
처음 ai 나올때만 해도 유료라서 시간좀 걸리겠네 했는데, 소스 오픈되고 나서.. 너도나도 야짤 만들어 보겠다고, 엄청 나게 달겨들고.. ai는 말도 안되는 속도로 발전함 ㅋㅋㅋㅋㅋ
(IP보기클릭)58.143.***.***
아무리 봐도 대학원생 와드
(IP보기클릭)118.40.***.***
이 수많은 공부가 오직 성욕해소를 위해서 쓰인다는점이 나를 흥분시킵니다
(IP보기클릭)218.37.***.***
| 23.02.13 02:36 | | |
(IP보기클릭)106.240.***.***
나도 ㅋ | 23.02.15 14:40 | | |
(IP보기클릭)210.92.***.***
와...
(IP보기클릭)116.42.***.***
AI 튜토리얼 ㅇㄷ
(IP보기클릭)221.153.***.***
읽진 않았지만 와드...
(IP보기클릭)218.150.***.***
(IP보기클릭)222.239.***.***
https://archive.md/Aj5ZQ 님의 개쩌는 글 박제했습니다 그저 감탄만 나오는군요
(IP보기클릭)222.239.***.***
(IP보기클릭)14.52.***.***
(IP보기클릭)112.159.***.***
(IP보기클릭)211.200.***.***
(IP보기클릭)218.38.***.***
(IP보기클릭)211.234.***.***
(IP보기클릭)58.126.***.***
(IP보기클릭)121.162.***.***
아직 공개되지는 않았지만 지금도 가능하기는 합니다. https://twitter.com/Yamkaz/status/1622724435211059203 | 23.02.13 12:40 | | |
(IP보기클릭)118.235.***.***
(IP보기클릭)106.101.***.***
(IP보기클릭)183.101.***.***
(IP보기클릭)1.242.***.***
(IP보기클릭)183.102.***.***
(IP보기클릭)221.150.***.***
(IP보기클릭)175.212.***.***
개쩐다
(IP보기클릭)175.212.***.***
AI와드 | 23.02.13 02:47 | | |
(IP보기클릭)115.140.***.***
처음 ai 나올때만 해도 유료라서 시간좀 걸리겠네 했는데, 소스 오픈되고 나서.. 너도나도 야짤 만들어 보겠다고, 엄청 나게 달겨들고.. ai는 말도 안되는 속도로 발전함 ㅋㅋㅋㅋㅋ
(IP보기클릭)172.226.***.***
(IP보기클릭)221.163.***.***
(IP보기클릭)211.178.***.***
(IP보기클릭)121.131.***.***
(IP보기클릭)1.244.***.***
AI도 제대로 하려면 기술자급이 되야되네
(IP보기클릭)114.200.***.***
(IP보기클릭)114.202.***.***
(IP보기클릭)211.209.***.***
(IP보기클릭)211.194.***.***
(IP보기클릭)59.10.***.***
(IP보기클릭)183.96.***.***
(IP보기클릭)219.250.***.***
(IP보기클릭)58.234.***.***
(IP보기클릭)220.94.***.***
(IP보기클릭)86.48.***.***
(IP보기클릭)221.141.***.***
(IP보기클릭)125.136.***.***
(IP보기클릭)61.84.***.***
(IP보기클릭)121.162.***.***
save_memory = True 설정하고 512 해상도에서도 메모리가 부족하다고 나오면 사양 부족입니다. 현재로서는 vram 8gb 이하에서는 사용할 수 없습니다. 콜렙 버전을 사용하는 방법도 있습니다. https://github.com/camenduru/controlnet-colab | 23.02.13 22:42 | | |
(IP보기클릭)61.84.***.***
감사합니다 일단 트루로 설정해볼게요 vram은 8기가 짜리긴한데 | 23.02.13 22:45 | | |
(IP보기클릭)106.101.***.***
(IP보기클릭)111.118.***.***
(IP보기클릭)121.162.***.***
이건 좀 지난 튜토리얼이라 이제 병합은 안 하셔도 됩니다. 자세한 내용은 18편을 참고하세요. https://bbs.ruliweb.com/community/board/300143/read/60397372?search_type=member_srl&search_key=3533827 | 23.02.27 19:39 | | |