
2. 이번에는 윈도우 Powershell을 일반 모드로 실행합니다(관리자 모드 아님)
아래의 텍스트들을 한 줄씩 순서대로 입력해줍니다.
중간 중간에 패키지를 다운 받고 설치해서 시간이 좀 걸리니 기다려줍니다.
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv --system-site-packages venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
마지막 accelerate config를 입력하면
잠시 뒤에 옵션 설정을 위한 메시지가 출력됩니다.
아래의 값을 순서대로 입력해줍니다.
0
나중에 최신버전으로 업데이트하려면 powershell이나 cmd를 실행하고 아래의 텍스트들을 순서대로 입력합니다.
cd kohya_ss
.\kohya_gui.cmd
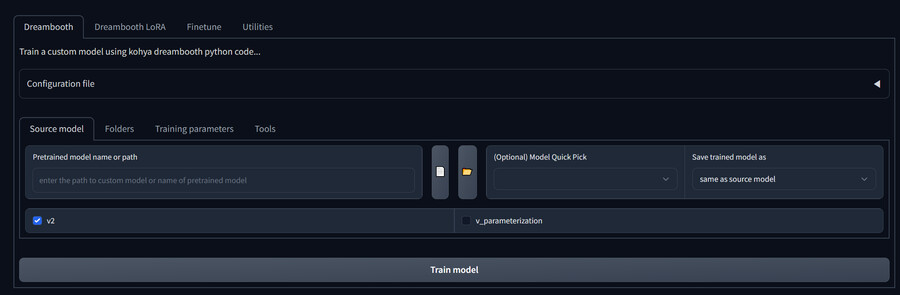
5. Dreambooth/Source model 탭에서 드림부스 학습에 사용할 베이스 모델을 지정할 수 있습니다.
-Pretrained model name or path : 베이스 모델의 경로를 지정합니다. 문서모양 아이콘을 클릭해서 모델 파일을 선택할 수 있습니다.
-Model Quicl Pick : 온라인에서 모델 파일을 다운받아서 학습에 사용합니다. 디폴트 SD가 리스트에 포함되어 있습니다.
-Save trained model as : 학습이 끝난 모델을 저장할 형식을 지정합니다. 주로 ckpt 또는 safetensor를 사용합니다.
-v2 : SD 2.0 이상 모델일 경우 사용합니다. 1.5나 1.4 베이스라면 해제해야 합니다.
-v_parameterization : SD 2.0 이상 모델일 경우 사용합니다. 1.5나 1.4 베이스라면 해제해야 합니다.

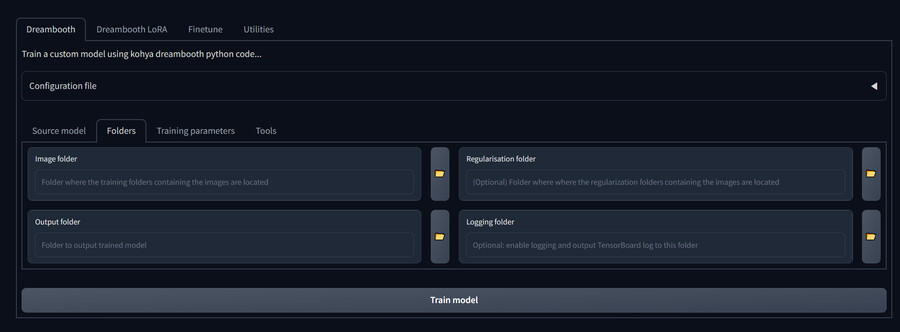
6. Folders 탭에서 학습용 이미지들이 위치한 폴더들의 경로를 지정할 수 있습니다.
-Image folder : 학습용 이미지가 위치한 경로입니다.
-Regularisation folder : 정규화 이미지가 위치한 경로입니다.
-Output folder : 학습이 끝난 모델 파일이 저장될 경로입니다.
-Logging folder ; 학습 로그가 저장될 폴더입니다.
각 이미지들의 용도와 준비하는 방법에 대해서는 10편을 참고하시기 바랍니다.
(AI) AI한테 원하는 캐릭터 학습시키기 튜토리얼 10 | 유머 게시판 | RULIWEB
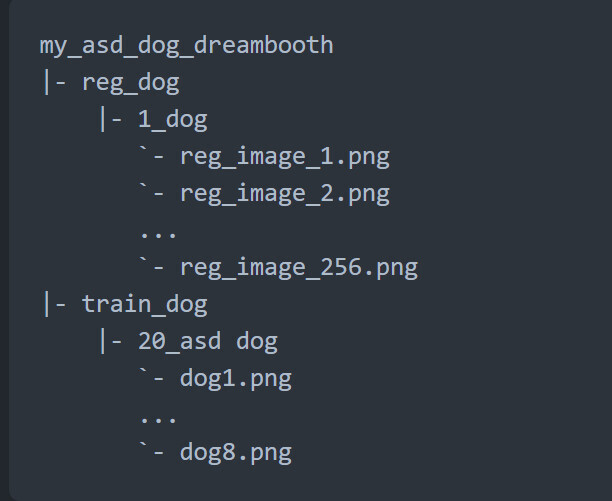
학습, 정규화 이미지의 폴더 이름 및 구조는 다음과 같습니다.
<임의의 학습 프로젝트 폴더 이름> 예 : train_shiroko
\<임의의 정규화 이미지 폴더 이름> 예 : reg_girl
\\<반복횟수>_<클래스> 예 : 1_girl (정규화 이미지)
\<임의의 학습 이미지 폴더 이름> 예 : train_shiroko
\\<반복횟수>_<토큰> <클래스> 예 : 1000_ba-shiroko girl (학습 이미지)
7. Kohya의 경우 학습 이미지 폴더들의 이름과 구조에 설정값이 포함되기 때문에 준비가 까다롭고 귀찮은 단점이 있습니다.
10편에서 소개할 당시에는 전부 하나씩 전부 수작업으로 준비할 필요가 있었지만 gui에서는 자동 기능이 추가됐습니다.
Dreambooth/Tools/Dreambooth/LoRA Folder preparation 탭에서 사용이 가능합니다.
-Instance prompts : 학습할 대상을 가리키는 태그를 입력합니다. 주로 sks-dog, ba-shiroko처럼 베이스 모델에 포함되지 않은 태그를 사용합니다.
-Class prompt : 학습 대상이 속한 클래스, 리트리버라면 dog, 고양이 장난감이면 toy, 미소녀 캐릭터면 girl 같이 속해있는 범주를 입력합니다.
-Training images ; 학습 이미지들이 위치한 폴더의 경로를 입력합니다. 폴더 아이콘을 눌러서 경로를 선택할 수 있습니다.
-Training images/Repeats: 각 이미지당 반복 학습 횟수를 지정합니다. 총 학습 횟수는 Repeats * 학습용 이미지 숫자 * epoch 가 됩니다. 정규화 이미지와 같은 숫자를 입력합니다.
-Regularisation images : 정규화 이미지들이 위치한 폴더의 경로를 입력합니다. 폴더 아이콘을 눌러서 경로를 선택할 수 있습니다.
-Regularisation images/Repeats: 각 이미지당 반복 횟수를 지정합니다. 일반적으로 1을 사용합니다.
-Destination training directory : 학습, 정규화 이미지들이 복사될 경로를 지정합니다. 폴더 아이콘을 눌러서 경로를 선택할 수 있습니다.
-Prepare training data : 위의 항목들에서 입력한 경로의 이미지를 복사해서 학습용 폴더를 생성합니다.
-Copy info to Folders Tab : 생성된 학습용 폴더의 정보를 자동으로 학습 설정탭에 복사합니다.
모든 항목들을 입력하시고 Prepare training data > Copy info to Folders Tab을 실행하시면 됩니다.
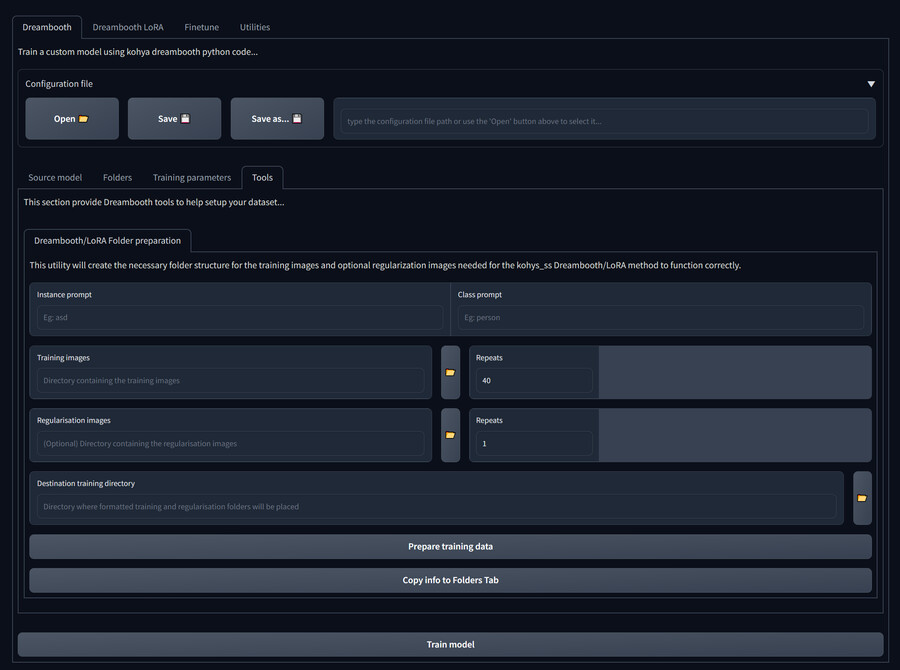
8. 7이 정상적으로 진행되면 Dreambooth/Folders 탭에 아래처럼 경로들이 복사되어 있습니다. 베이스 모델을 지정하고 학습 이미지도 준비됐으면 다음으로 넘어갑니다.
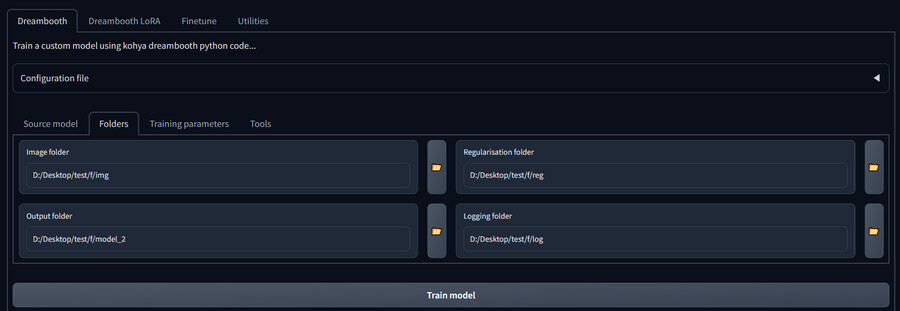
9. Dreambooth/Training parameters 탭에서 학습에 필요한 값들을 설정합니다.
-Learning rate : 학습 강도를 지정합니다. 높으면 빠르지만 이미지가 금방 깨질 위험이 있고 낮으면 안정적이지만 느려집니다. 일반적으로 1e-06 (0.000001) 을 가장 많이 사용합니다.
-LR Scheduler : Learning rate를 학습 스텝에 따라 변경하는 방식을 지정합니다. 일반적으로 constant를 많이 사용합니다.
-LR warmup : LR을 변경할 학습 스텝 수를 지정합니다. 학습스텝 * 1/LR warmup(스텝/퍼센트)입니다. constant 에서는 0을 사용합니다.
-Train batch size : 한번에 학습되는 이미지의 숫자를 지정합니다. 높을수록 학습이 빨라지지만 Vram 사용량도 올라갑니다.
-Epoch : 전체 학습이미지가 모두 학습되는 횟수를 지정합니다. 학습이미지 숫자 * 정규화 이미지 숫자 * Epoch * 2= 학습 스텝 입니다.
-Save every N epochs : 학습 중간에 모델을 저장할 epoch 간격을 지정합니다.
- Mixed precision : 최적화 옵션입니다. fp16을 주로 사용합니다.
-Number of CPU threads per process : 사용할 CPU 쓰레드 숫자를 입력합니다. 컴퓨터 사양에 맞게 입력합니다.
-Seed: 학습에 사용할 시드값입니다. 기본값을 그대로 사용해도 무방합니다.
-Max resolution : 학습용 이미지 해상도를 지정합니다.
-Caption Extension : 캡션 파일의 확장자를 지정합니다.
-Enable buckets : 여러 해상도와 비율의 이미지를 학습할 때 사용하는 옵션입니다. 64의 배수의 해상도로 이미지를 분류하고 튀어나온 부분은 잘라냅니다.
-Cache latent : 체크 해제시 Vram 사용량이 조금 줄어들고 학습 속도가 느려집니다.
-Use 8bit adam : 최적화 옵션입니다.
-Use xformers : 최적화 옵션입니다.
-Advanced Configuration : 추가 옵션들이 있는 항목입니다.
-Full fp16 training (experimental) : 검증되지 않은 실험 기능입니다. 사용을 권장하지 않습니다.
-No token padding : 토큰 패딩을 비활성화합니다. 기본값은 off 입니다.
-Gradient checkpointing : 최적화 옵션입니다. 활성화시 vram 사용량이 조금 줄고 대신 학습 속도가 늘려집니다.
-Shuffle caption : 캡션의 순서를 임의로 섞습니다. 캡션 파일에 입력된 태그들은 앞에서부터 순서로 영향이 강한데 이 옵션을 사용하면 골고루 영향을 가지도록 할 수 있습니다. 태그가 많을 경우 사용합니다.
-Save training state : 나중에 이어서 학습을 진행할 수 있도록 모델과 같은 경로에 last-state 폴더를 생성합니다.
-Color augmentation : 스텝마다 학습 이미지의 색상을 조금씩 임의로 변경합니다. 학습 이미지가 매우 적을 때 사용합니다.
-Flip augmentation : 학습시 랜덤하게 학습 이미지를 뒤집습니다. 학습 이미지가 매우 적을 때 사용합니다.
-Clip skip : 베이스 모델의 학습에 사용된 것 같은 값을 사용합니다. Nai의 경우 2, SD는 1입니다.
-Resume from saved training state : 지난 학습을 이어서 진행합니다. Save training state 옵션을 사용해서 학습할 경우 생성되는 last-state 폴더의 경로를 입력합니다.
-Prior loss weight : 기본값 1을 사용합니다.
10. 마지막으로 Train model 버튼을 누르면 학습이 시작됩니다.
학습이 끝난 모델 파일은 Output folder에 저장됩니다.
상단의 Configuration file 탭에서 현재 설정을 json 파일로 저장할 수 있습니다.
Open으로 불러오고 Save로 저장합니다. Save as는 다른이름으로 저장입니다.
이제 Lora 사용법에 대해 알아봅시다.
전체적인 구성은 Dreambooth와 동일합니다.
1. Dreambooth LoRa 탭으로 이동합니다.
Source model, Folder의 항목들은 위에서 설명한 드림부스와 같은 방식으로 지정하시면 됩니다.
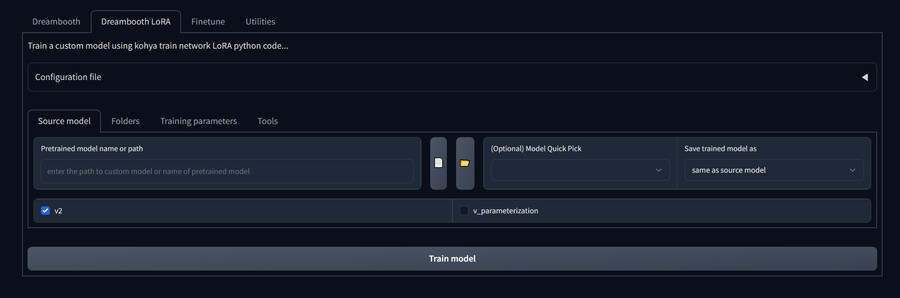
2. Training parameters 탭의 아래 항목들을 제외하면 나머지는 드림부스와 동일합니다.
-Text Encoder learning rate : 텍스트 인코더의 학습 레이트를 지정합니다. 5e-5 정도가 적당합니다. Unet learning rate의 1/2 정도가 좋다는 보고도 있습니다.
-Unet learning rate: Unet 학습 레이트를 지정합니다. 1e-3 이나 1-e4가 주로 사용됩니다.
-Network Dimension : Lora 차원수를 지정합니다. 높을수록 표현력이 좋아지지만 학습시간과 vram 사용량이 늘어납니다. 4~8가 적당합니다.
설정이 완료되면 Train model을 눌러서 학습을 시작합니다. Vram이 약 6~8gb 정도 필요합니다.
3. 학습이 끝나면 Output folder에 .pt 파일이 저장됩니다. 약 10mb 정도 됩니다.
Lora 파일을 사용하려면 모델 파일에 병합할 필요가 있지만 익스텐션을 사용하면 그대로 사용할 수 있습니다.
이 익스텐션은 kohya를 사용해서 학습한 Lora만 호환됩니다. Webui 익스텐션으로 학습한 Lora는 사용이 불가능합니다.
익스텐션 : kohya-ss/sd-webui-additional-networks (github.com)
(Automatic1111 webui 기준입니다. : AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)
Webui에서 Extensions / Install from URL 탭으로 이동한 다음 URL for extension's git repository에 익스텐션의 주소를 입력하고 install 버튼을 누릅니다.
설치가 완료되면 webui를 다시 시작합니다.
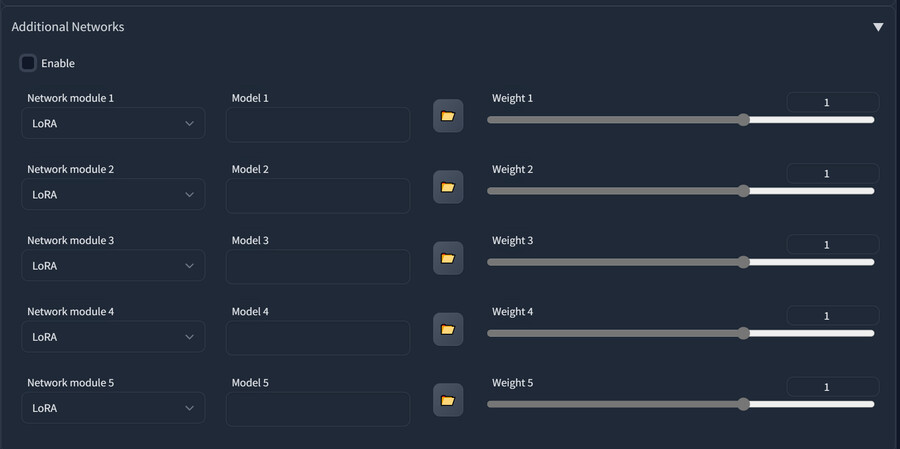
이제 아래쪽에 아래 이미지와 같은 탭이 추가됩니다, 사용법은 다음과 같습니다.
-Enable ; Lora 기능을 활성화합니다.
-Netwrok module 1~5 : 사용할 네트워크 모듈의 타입을 지정합니다, 현재는 Lora만 지원합니다.
-Model 1~5 : Lora 파일의 경로를 입력합니다.
-Weight : Lora의 강도를 지정합니다. -1 ~ 2 까지 지정할 수 있습니다.
4. 드림부스와 동일하게 instance prompt를 입력해서 이미지를 생성합니다.
Model은 Lora 학습에 사용한 베이스 모델을 사용합니다. 다른 모델을 사용해도 이미지가 생성되기는 하지만 좀 다르게 나옵니다.
같은 설정의 드림부스와 비교했을 때 이미지 표현력의 차이는 다음과 같습니다.
캐릭터의 특징은 둘다 잘 표현하고 있지만 Lora 쪽은 머리 위의 헤일로가 생성되는 빈도가 낮습니다.

Weight를 조정하면 아래와 같은 이미지가 생성됩니다.
-1.0 / -0.5/ 0.0 / 0.5 / 1.0/ 1.5/ 2.0

Netwrok module을 여러 개 사용해서 복수의 Lora를 동시에 적용할 수 있습니다.
ba-shiroko와 외곽선을 강조하는 Lora를 각각 1과 2에 지정하고 이미지를 생성하면 아래와 같은 이미지가 생성됩니다.
1개 사용 / 2개 사용

Lora 파일 2개를 병합하는 것도 가능합니다.
Kohya GUi의 Utilities / Merge LoRa 탭으로 이동.
-LoRA model "A" : 베이스 Lora 파일의 경로를 지정.
-LoRA model "B" : A에 더할 Lora 파일의 경로를 지정.
-Merge ratio : 병합 비율을 지정. 0.7이면 A가 70프로 B가 30프로로 병합됩니다.
-Save to : 병합된 Lora 파일이 저장될 경로를 지정합니다.
-Merge precison : 병합시 정밀성을 지정합니다. Float가 기본값이지만 메모리가 부족할 경우 fp16을 사용합니다.
-Save precison : 병합된 파일의 정밀성을 지정합니다. FP16을 사용하면 정밀성이 좀 떨어지는 대신 용량이 줄어듭니다. 기본값은 float 입니다.
A / B / A 0.6 + B 0.4

드림부스로 학습된 모델파일에서 학습된 내용을 Lora 파일로 추출하는 것도 가능합니다.
학습된 모델 A - 베이스 모델 B 의 방식으로 A와 B의 차이를 lora 파일로 추출합니다.
실험 기능이라 좀 애매하게 나옵니다.
Kohya GUi의 Utilities / Extract LoRA 탭으로 이동.
-Finetuned model : 학습된 모델 파일의 경로를 지정합니다.
-Stable Diffusion base model : 베이스 모델 파일의 경로를 지정합니다.
-Save to : 추출된 Lora 파일이 저장될 경로를 지정합니다.
-Save precison : 저장될 Lora 파일의 정밀성을 지정합니다. FP16을 사용하면 파일 용량이 조금 줄어듭니다. 기본은 Float입니다,
-Network Dimension : Lora 차원 수를 지정합니다. 기본값은 8입니다.
-v2 : 모델의 베이스가 SD 2.0 이상일 경우 사용합니다.
Extract LoRA model 버튼을 누르면 추출이 진행됩니다.
베이스모델 / 드림부스 / Lora / 추출한 Lora + 베이스 모델

(IP보기클릭)121.163.***.***
(아하 완벽히 이해했어 콘)
(IP보기클릭)211.200.***.***
(IP보기클릭)218.53.***.***
전문지식 추천
(IP보기클릭)121.163.***.***
(아하 완벽히 이해했어 콘)
(IP보기클릭)218.53.***.***
전문지식 추천
(IP보기클릭)211.200.***.***
(IP보기클릭)121.162.***.***
5700323
확실이 kohya 쪽이 좀 더 잘 나옵니다. 왼쪽이 드림부스 오른쪽이 D8 익스텐션으로 학습된 Lora 입니다. | 23.01.09 02:20 | | |
(IP보기클릭)218.158.***.***
(IP보기클릭)218.158.***.***
혹시 저사양 그래픽카드 버전 말고 메인스트림 글카 환경에서 로컬로 학습시키기 관련 글 쓰신거 있나요? | 23.01.09 00:38 | | |
(IP보기클릭)121.162.***.***
vram 12gb 이상의 그래픽카드를 가지고 계신다면 드림부스를 사용하실 수 있습니다. 본문 중간에 나와있는 GUI 드림부스탭 설정법과 10편의 학습 이미지 및 캡션 준비하기 부분을 참고하시는 것을 추천합니다. https://bbs.ruliweb.com/community/board/300143/read/59499900?search_type=member_srl&search_key=3533827 | 23.01.09 02:02 | | |
(IP보기클릭)121.184.***.***
ㄱㅅㄱㅅ ㅇㄷ | 23.01.09 02:12 | | |
(IP보기클릭)110.12.***.***
(IP보기클릭)121.162.***.***
엔비디아 그래픽카드가 필요합니다. | 23.01.09 01:58 | | |
(IP보기클릭)110.12.***.***
꿱 | 23.01.09 01:59 | | |
(IP보기클릭)118.35.***.***
(IP보기클릭)218.158.***.***
(IP보기클릭)121.162.***.***
Enable buckets 옵션을 사용할 경우 자동으로 해상도별로 이미지를 분류해서 학습을 하기 때문에 1:1(512x512) 이외의 이미지가 포함되어 있어도 괜찮습니다. Vram 사용량은 이미지 해상도가 높을수록 같이 늘어납니다. | 23.01.15 15:26 | | |
(IP보기클릭)218.158.***.***
지금 3060 12gb로 드림부스 찍먹하려고 하는데 자꾸 터집니다 아예 시작조차 안돼서 뭐가 문젠지 모르겠음 ㅠㅠ 데이터셋이 난잡한게 문제는 아닌거같네요 감사합니다 | 23.01.15 15:27 | | |
(IP보기클릭)121.162.***.***
12gb면 딱 최소사양이네요. 일단 아래 옵션들을 설정하고 그래픽 카드를 사용하는 다른 프로그램들을 전부 종료해서 테스트해보세요. gradient_checkpointing Use 8bit adam Use xformers Cache latent Mixed precision = fp16 Train batch size = 1 그래도 계속 메모리가 부족하다면 Full fp16 training (experimental) 를 사용하는 방법도 있습니다. 이 옵션을 사용하면 vram 사용량이 대폭 줄어드는 대신 정확도가 떨어져서 더 오랫동안 학습할 필요가 있습니다. | 23.01.15 15:37 | | |
(IP보기클릭)218.158.***.***
Cache latent는 Step Ratio of Text Encoder Training를 1로 설정하는거 맞죠? | 23.01.15 15:39 | | |
(IP보기클릭)218.158.***.***
혹시 그래픽카드를 사용하는 다른 프로그램들의 예시엔 뭐가 있나요 크롬 창 탭 많아도 글카 쓰나요? | 23.01.15 15:40 | | |
(IP보기클릭)121.162.***.***
Stop text encoder training 값은 어느 스텝 이후에 Text encoder 학습을 중단할지 지정하는 용도입니다. 0으로 설정하면 사용되지 않습니다. 최적화하고는 상관이 없습니다. | 23.01.15 15:41 | | |
(IP보기클릭)121.162.***.***
웹브라우저, 월페이퍼엔진, 유튜브 등이 있습니다. | 23.01.15 15:43 | | |
(IP보기클릭)218.158.***.***
감사합니다 | 23.01.15 15:45 | | |
(IP보기클릭)121.146.***.***
(IP보기클릭)1.245.***.***
(IP보기클릭)121.162.***.***
여기서 소개한 Lora 도구는 폴더명을 사용해서 학습 스텝을 지정합니다. 50_girl 이고 epoch가 10이면 총 500스텝을 학습하게 됩니다. 정규화 이미지를 사용하면 그 숫자만큼 학습 이미지에 추가되고 스텝이 증가하게 됩니다. 학습을 시작하면 이러한 계산을 거쳐서 총 학습스텝이 cmd에 표시되는데 이 스텝 수가 원하시는 3000이 되어야 합니다. 20만이 아니라 3천이 나오도록 폴더 이름에 지정한 스텝을 줄여보세요. | 23.02.18 18:10 | | |
(IP보기클릭)1.245.***.***
해결됐습니다 정말 감사합니다~~~ | 23.02.18 20:06 | | |
(IP보기클릭)175.197.***.***