

SeamlessStreaming
소리있음 (1분12초부터 스페인어를 영어로, 프랑스어를 영어로 번역하는 것을 실시간으로 보여줌)
SeamlessStreaming은 동시번역(음성-음성)에 약 2초의 지연 시간과, 오프라인 모델과
거의 동일한 정확도로 번역을 제공하는 최초의 대규모 다국어 모델입니다.
SeamlessM4T v2를 기반으로 구축된 SeamlessStreaming은
거의 100개 입력 언어와 36개 출력 언어에 대한 음성-음성 번역 외에도
거의 100개 입력 및 출력 언어에 대한 자동 음성 인식 및 음성-텍스트 번역을 지원합니다.
※2초의 지연시간은 사실상 인간 동시통역가가 옆에 붙어있는것과 같은 수준
https://ai.meta.com/resources/models-and-libraries/seamless-communication-models/#seamlessstreaming
SeamlessExpressive
번역은 인간 표현의 뉘앙스를 포착해야 합니다.
기존 번역 도구는 대화 내 콘텐츠를 캡처하는 데 능숙하지만
일반적으로 출력을 위해 단조로운 로봇식 텍스트 음성 변환 시스템에 의존합니다.
SeamlessExpressive는 말의 복잡성을 보존하는 것을 목표로 합니다.
보컬 스타일과 감정적인 톤 외에도 일시정지, 말하는 속도 등이 포함됩니다.
https://seamless.metademolab.com/expressive
SeamlessM4T
메타는 2023년 8월에, 음성과 텍스트 전반에 걸쳐 번역 및 전사에 대한 최첨단 결과를 제공하는
기본 다국어 및 멀티태스킹 모델인 SeamlessM4T의 첫 번째 버전을 출시했었습니다.
이 작업을 바탕으로 개선된 모델인 SeamlessM4T v2는
새로운 SeamlessExpressive 및 SeamlessStreaming 모델의 기반이 됩니다.
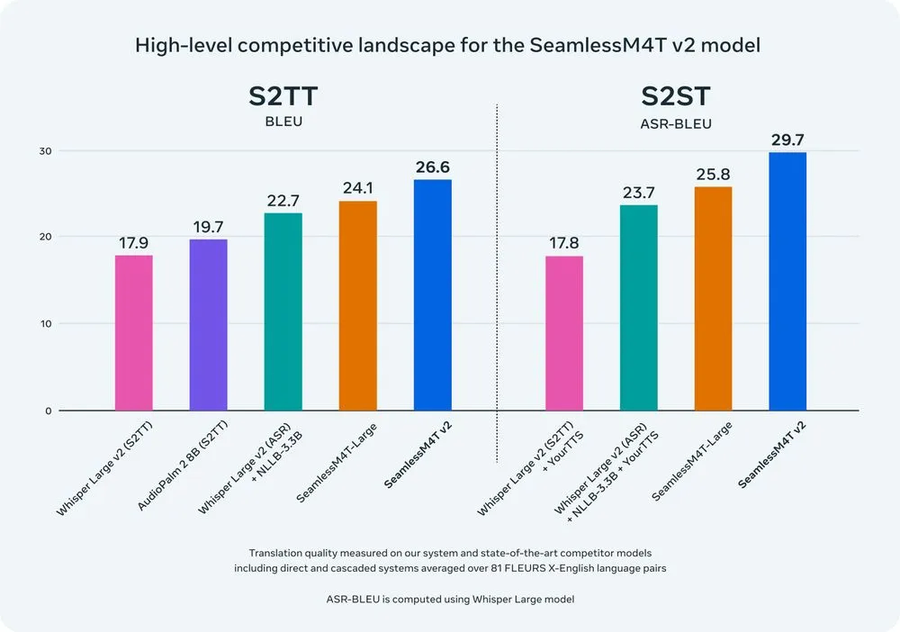
업그레이드된 기본 다중 언어 및 다중 작업 모델인 SeamlessM4T v2는 자동 회귀가 아닌
텍스트 단위 디코더를 갖추고 있습니다.
w2v-BERT 2.0 인코더는 100만 시간 동안 훈련된 이전 버전과 비교하여 450만 시간의 음성 데이터로 훈련되었습니다.
또한 SeamlessM4T v2는 자원이 적은 언어에 대해 SeamlessAlign의 더 많은 데이터로 보완됩니다.
SeamlessM4T v2는 자동 측정항목(BLEU, ASR-BLEU, BLASER 2 등)을 사용하여 모든 작업 및 언어에 걸쳐
철저하게 평가되었으며, 이전 최첨단 모델보다 훨씬 뛰어난 성능을 보였습니다.
또한 견고성, 편견 및 환각 독성에 대한 테스트도 거쳤습니다.
Seamless
Seamless는 SeamlessM4T v2의 품질과 다국어 지원, SeamlessStreaming의 낮은 대기 시간,
SeamlessExpressive의 표현 보존 기능을 하나의 통합 시스템으로 통합합니다.
이는 시스템이 부분 입력에만 액세스할 수 있는 스트리밍에서 특히 어려울 수 있는
보컬 스타일과 운율을 모두 유지하는 최초의 스트리밍 번역 모델입니다.
https://github.com/facebookresearch/seamless_communication
현재 모델이 공개되어서 관심이 있으면 데모를 시연해보거나 코랩 등으로 직접 돌려볼수도 있습니다.
그리고 최근 메타 AI 10주년 행사에서 퀘스트3에서 단독으로 실시간 번역기능이 로컬로 실행되었습니다.
(IP보기클릭)222.233.***.***