


코어 간 지연 : 코어 i5 관련 문제
인텔의 Comet Late 10th Gen Core 부품을 위해 이 회사는 대부분의 프로세서 라인에 대해 각각 10 개의 코어와 6 개의 코어가 있는 두 개의 서로 다른 실리콘 다이를 만들고 있습니다. 8 및 4 코어 부품을 생성하기 위해 다른 코어가 비활성화됩니다. 이것은 새로운 것이 아니며, 새로운 실리콘 디자인의 수를 최소화하고 실리콘에 약간의 중복성을 구축하고 대부분을 가능하게 하기 위해 AMD와 인텔 모두에서 10 년 동안 가장 큰 부분을 차지했습니다. 결함이 발견되더라도 웨이퍼를 판매할 수 있습니다.
Comet Lake의 경우 인텔은 실리콘을 분할하여 모든 10 코어 Core i9 및 8 코어 Core i7 프로세서가 예상대로 10c 다이로 구성되고 6 코어 Core i5 및 4 코어 Core i3 프로세서가 6c 다이로 제작되었습니다. 이 규칙에 대한 유일한 예외는 코어 i5-10600K / KF 프로세서로, 코어 4 개가 비활성화 된 10 코어 다이를 사용하여 총 6 코어를 제공합니다. 이로 인해 잠재적인 문제가 발생합니다.
따라서 10c 다이는 시스템 에이전트 (DRAM, IO) 및 그래픽에 의해 각 끝에 캡핑된 5 개의 코어로 구성된 2 열로, 실리콘의 다른 부분에 도달하기 위해 데이터가 통과해야하는 12 개의 스톱 링을 생성한다고 상상해보십시오. 간단하게 시작하고 8c 프로세서를 만들기 위해 두 개의 코어를 비활성화한다고 상상해보십시오. 최고 / 최악의 코어 간 지연 시간을 얻기 위해 최상의 / 최악 사례 시나리오를 추측하는 것은 매우 간단 할 수 있습니다.

다른 최악의 8c 경우는 코어 0을 활성화 한 다음 코어 1과 코어 2를 비활성화하고 코어 3-9는 활성화 된 상태로 유지하는 것입니다.
그런 다음 원래 10 코어 설정에서 4 개의 코어를 비활성화 할 수 있습니다. 4 개의 코어가 될 수 있으므로 최악의 시나리오와 최상의 시나리오를 상상해보십시오.
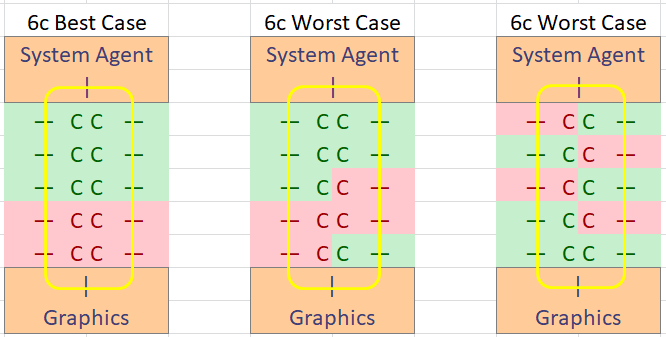
왼쪽에는 모든 코어 간 지연 시간을 최소화하는 최상의 케이스 배열이 있습니다. 중간에는 최악 중 최악의 경우가 있으며, 왼쪽 상단의 첫 번째 코어에 대한 모든 접촉은 코어에서 이동하는 거리가 멀수록 대기 시간이 훨씬 길어집니다. 오른쪽에는 불균형 디자인이지만 대기 시간의 변화가 적을 수 있습니다.
인텔이 코어를 비활성화하여 이러한 8c 및 6c 디자인을 만들었을 때, 회사는 과거에 비활성화하면 나머지 프로세서는 '유사한 성능 목표를 가지도록' 나머지 프로세서는 그대로 두고 다른 개별 장치는 다른 코어를 비활성화 할 수 있다고 약속했습니다. 모두 합리적인 스펙트럼에 속합니다.
코어 i5-10600K 코어 투 코어 레이턴시 차트부터 시작하겠습니다.
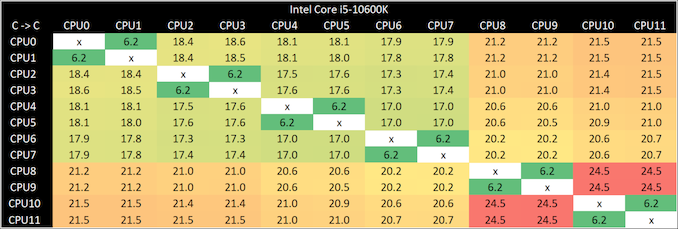
(역자 주: 이 표에서 CPU0, CPU1 이라는 건 각각의 쓰레드를 말합니다. 따라서 CPU0과 CPU1은 같은 코어 내의 두 쓰레드고, 인접한 코어라는 것은 CPU0/CPU1 코어와 CPU2/CPU3 코어가 서로 인접해 있다는 뜻입니다. 두 개씩 묶어서 보세요. 코어를 0~5번이라고 하면 0~3번 코어 사이에서는 레이턴시가 17~18나노초, 0~3번과 4, 5번 코어끼리는 레이턴시가 20~21나노초, 4번과 5번 코어끼리는 레이턴시가 24나노초라는 뜻입니다.)
인접한 코어는 충분히 보이면 링 주위를 더 길게 여행 할 때마다 각 정류장마다 약 1 나노초가 걸립니다. 마지막 2 코어까지 이르면 갑자기 4 나노초 점프합니다. 여기에 우리가 보유한 프로세서는 코어 간 지연 시간에 치명적이며 결국 스레드가 지연되는 두 코어에 배치되면 성능에 문제가 있을 수 있습니다.
이제 이 결과로 약간의 열기를 얻는 것이 매우 쉽습니다. 불행히도 우리는 이를 비교할 '이상적인' 6c 디자인을 가지고 있지 않기 때문에 성능을 비교하는 것이 약간 까다롭습니다. 그러나 이는 다른 Core i5-10600K 샘플간에 차이가 있을 수 있음을 의미합니다.
효과는 여전히 8 코어 Core i7-10700K에서 발생하지만 덜 두드러집니다.
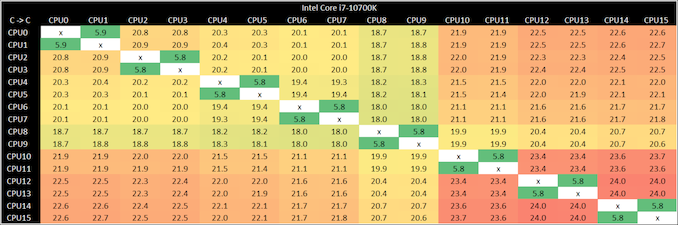
다른 5 개의 코어와 비교하여 마지막에 3 개의 코어 사이에는 여전히 상당한 점프가 있습니다. 테스트에서 불행한 단점 중 하나는 코어가 나열된 물리적 위치와 일치하지 않으므로 칩의 정확한 레이아웃을 알기가 어려울 수 있다는 것입니다.
큰 10 코어 프로세서로 이동하면 흥미로운 결과를 얻을 수 있습니다
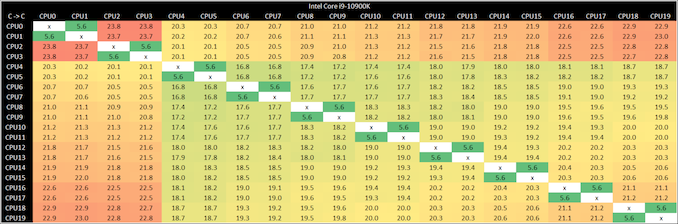
지연 시간이 꾸준히 증가해야 하지만 두 개의 코어에서 3-4 나노초로 여전히 점프합니다. 이것은 다르지만 복합적인 문제를 지적합니다.
우리의 가장 좋은 추측은 이 두 개의 여분의 코어가 Comet Lake의 이런 종류의 링 디자인에 최적화되어 있지 않다는 것입니다. 코어의 프로세서 라인업을 위해 인텔은 링 버스를 코어 간의 주요 상호 연결로 10 년 이상 사용해 왔으며 일반적으로 4-6 코어 프로세서에서 볼 수 있습니다. 인텔은 또한 최대 24 코어의 칩으로 엔터프라이즈 프로세서에서 링 버스를 사용했지만 코어-코어 간 지연 시간을 줄이기 위해 듀얼 링 버스를 사용했습니다. 인텔은 단일 링에 최대 12 개의 코어를 배치했지만, 회사는 일반적으로 링당 8 개 이하의 코어 설계를 유지하는 것을 선호하는 것으로 보입니다.
인텔이 이러한 엔터프라이즈 칩을 위해 그렇게 할 수 있다면 10 코어 Comet Lake 디자인은 어떨까요? 소비자 Skylake 프로세서에 적용된 원래의 링 설계는 코어 수가 4 개일 때 코어 수가 증가함에 따라 선형으로 확장되지 않기 때문입니다. 코어 실리콘 설계를 4 개에서 6 개로, 6 개에서 8 개로 이동함에 따라 대기 시간이 눈에 띄게 증가하지만 10 코어 링은 한 걸음 떨어져 있으며 더 큰 지지를 위해 링에 추가 리피터가 필요합니다.
코어의 IO 부분 또는 PCIe 레인과 업무를 공유하는 등 링의 해당 섹션에서 추가 기능을 갖는 이러한 코어에 대한 설명도 있을 수 있으며 결과적으로 추가 캐시 라인 전송에 추가 주기가 필요합니다.
인텔의 스카이 레이크 소비자 라인 프로세서에 대해서는 모든 링 라인 상호 연결의 한계에 도달했습니다. 인텔이 향후 프로세서를 위해 12 코어 버전의 Skylake 소비자를 만들 경우, 단일 링 인터커넥트는 추가 대기 시간 페널티 없이 처리 할 수 없으며, 링을 조정하지 않으면 더 큰 페널티가 될 수 있습니다. 동일한 링과 메모리가 더 많은 코어를 지원해야하므로 대역폭 문제도 있습니다. 인텔이 이 경로를 계속 따르면 듀얼 링을 사용하거나 다른 상호 연결 패러다임 (메시, 칩렛)을 사용하거나 새로운 마이크로 아키텍처 및 상호 연결 디자인으로 완전히 이동해야합니다.
요약:
10세대 인텔 프로세서는 2코어만 유독히 레이턴시가 긴데 기존 8코어 부분만 최적화가 잘된 것 같습니다.
i5-10600K는 첨부터 6코어로 찍은 칩과 10코어에서 4코어를 불능시킨 칩 사이에 성능 차이가 날 수 있습니다.
불능으로 된 코어의 배치에 따라서도 레이턴시가 길어지는 코어가 있을 수 있습니다.
(IP보기클릭)121.167.***.***
수율뽑기에 이은 코어 뽑기라니
(IP보기클릭)59.14.***.***
그냥 무조건 라이젠으로...
(IP보기클릭)112.168.***.***
애초에 인텔 지들도 저문제 알고있어서 스카이떄부턴가 익스트림라인업은 메쉬구조 썼었죠 4코어 기준으로 돌리던거 6코어 8코어까진 어떻게 버텼을지 몰라도 2.5배가까이 되다보니 답안나오나 보네요
(IP보기클릭)58.233.***.***
이래서 9900k가 10700k 이기는것도 생기는거였구나..
(IP보기클릭)121.167.***.***
링버스가 늘어난거에 더불어 비활성 코어 위치에 따라 활성코어의 레이턴시가 더 늘어난다는 괴랄한 구조라는 거됴
(IP보기클릭)121.168.***.***
(IP보기클릭)121.167.***.***
수율뽑기에 이은 코어 뽑기라니
(IP보기클릭)125.141.***.***
(IP보기클릭)125.137.***.***
(IP보기클릭)211.202.***.***
(IP보기클릭)121.167.***.***
metierr
링버스가 늘어난거에 더불어 비활성 코어 위치에 따라 활성코어의 레이턴시가 더 늘어난다는 괴랄한 구조라는 거됴 | 20.05.24 22:15 | | |
(IP보기클릭)14.43.***.***
(IP보기클릭)211.48.***.***
(IP보기클릭)59.14.***.***
그냥 무조건 라이젠으로...
(IP보기클릭)211.219.***.***
라이젠은 2 CCX라 그냥 태생이 WORST of WORST인데?? 비빌 걸 비벼야지 | 20.05.25 05:36 | | |
(IP보기클릭)211.219.***.***
인텔은 꽃게 1마리인데 다리가 10개이냐 8개이냐 몇번째다리가 없는가에 따라 가치가 다른거고 AMD는 애초에 정상인 게가 거의 없어서 작은 사이즈로 1+1로 두마리 준다는것임 그래서 레이턴시가 엄청 오르는거고. 그래서 게임에서 느린것임 | 20.05.25 05:38 | | |
(IP보기클릭)118.129.***.***
하지만 작업 성능과 가격은??? | 20.05.25 12:06 | | |
(IP보기클릭)58.233.***.***
이래서 9900k가 10700k 이기는것도 생기는거였구나..
(IP보기클릭)112.168.***.***
애초에 인텔 지들도 저문제 알고있어서 스카이떄부턴가 익스트림라인업은 메쉬구조 썼었죠 4코어 기준으로 돌리던거 6코어 8코어까진 어떻게 버텼을지 몰라도 2.5배가까이 되다보니 답안나오나 보네요
(IP보기클릭)14.39.***.***
(IP보기클릭)39.7.***.***
캐미화이트
음... 인텔은 비활성화된 코어는 레이저 커팅을 하는 걸로 아는지라... 그 정도까진 아닐 거예요(다만 레이저 커팅 안하고 그냥 코어 죽이고 나온거면 얘기가 다름) | 20.05.25 01:11 | | |
(IP보기클릭)211.252.***.***
캐미화이트
라이젠의 코어간 레이턴시를 알아보시면 알겠지만... 저건 그래도 빠른겁니다. | 20.05.25 02:32 | | |
(IP보기클릭)39.7.***.***
(IP보기클릭)220.71.***.***
라이젠은 동일CCD 내 다른CCX끼리는 80ns 이상 걸리고 다른 CCD간에는 110ns 이상 걸림 20ns대 나오는 거 가지고 인텔 구리네 할 상황은 아님
(IP보기클릭)220.71.***.***
오히려 레이턴시의 균일성으로 보면 인텔이 낫고 스케줄링 하기에도 편함. 라이젠이 상대적으로 훨씬 개판이지. | 20.05.25 08:54 | | |
(IP보기클릭)123.213.***.***
본문은 인텔이 AMD보다 레이턴시가 구리다는 이야기가 아닌데요. 그나저나 이 문제를 해결하려고 젠3는 8코어 단일 CCX구조로 나온다는 루머가 있는데 제발 | 20.05.25 09:13 | | |
(IP보기클릭)223.62.***.***
멜트릴리스
그것도 좀 이해가 되는게 인텔 6코어는 시기문제지 예정되어 있었지만 8코어나 10코어로 늘려주게 해줘서 경쟁도 되게 싸우게 만들어줬을 정도에 성능도 적당하니 그런 분들 늘었는데 인텔 망해라고하는건 너무갔죠. 경쟁은 필요하고 과거 AMD가 독주하던시절의 CPU가격보면 답이 없었으니 경쟁은 필요한데말이죠 | 20.05.25 12:08 | | |
(IP보기클릭)175.193.***.***
이 댓글 보고 위의 라이젠 찬양 댓글 보고 오니 기도 안차네요. | 20.05.25 12:56 | | |
(IP보기클릭)1.237.***.***
여긴 바이럴ㅅㄲ들 정지 먹일 생각도 없는듯ㅋㅋ | 20.05.25 13:09 | | |
(IP보기클릭)175.223.***.***
(IP보기클릭)222.119.***.***
(IP보기클릭)222.108.***.***