


이걸 보는 순간
AI 연구자들은 "이게 돼?"를 외치고
저자를 붙잡고 뭐가 어떤 상황인지 소리지르기 시작함.
https://arxiv.org/pdf/2402.17764.pdf
논문링크
이게 뭐냐면 그 역사를 좀 많이 거슬러올라야 하는데
ai는 2010년대 초반부터 계속 모든 연산을 행렬연산으로 했었음
https://bbs.ruliweb.com/community/board/300779/read/45041511
내가
2019년에 올린 고려대학교 ai 연구 소개에서 사용된 트랜스포머도
바로 이 행렬연산을 쓰는 방식임.
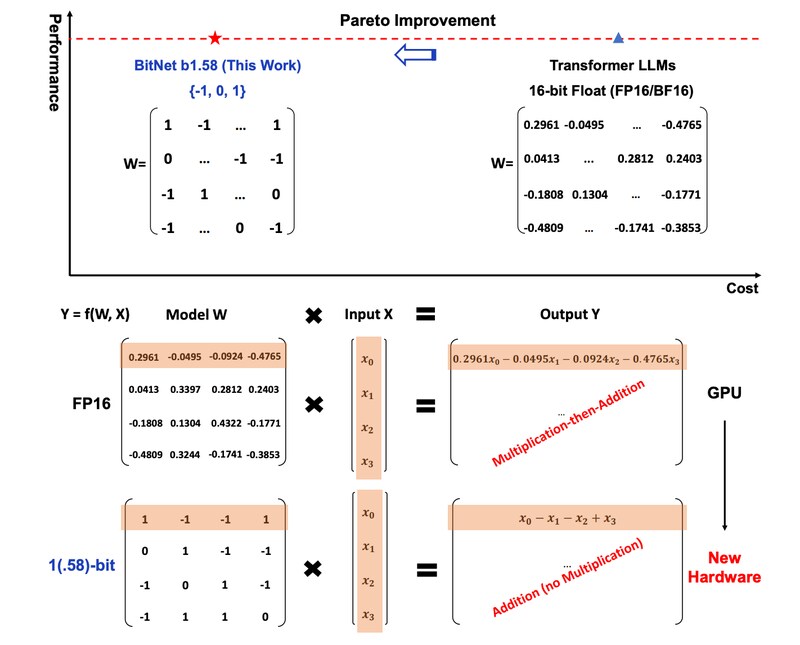
근데 이걸 0,1,-1으로 대강 반올림하고 해도 원본과 똑같은데? 같은 소리를 한 거야.
근데 이러면 속도가 몇 배 정도가 아니라
GPU 안 써도 되지 않나? 까지 넘어감
이걸 이 기술 모르는 사람을 위해 설명해주자면
레시피에 고기 몇그람 후추 몇그람 이렇게 되어있는데
대강 막 손에 잡히는 대로 해서 넣었더니 더 편하고 맛있는데?
약불로 3시간 구우라는거 강불로 10분 구웠더니 더 맛있는데?
같은 소리를 한 거임.
지금 그래서 이거 검증에 전세계가 바쁜 상황임.
보통은 씹는데 천하의 구글이 발표한지라....
그리고 난 지금 그게 맞는지 보는 중이고!
지금 놀라운 게 4090 하나에다가 완전학습 돌리는데
원래 이 gpu에는 못 돌리는 완전학습이 느리게나마 돌아가고 있어.....
하하 야근이다

(IP보기클릭)114.203.***.***
그니깐 너가 스카이넷 개발자중 하나라는거지?? 암살한다
(IP보기클릭)220.70.***.***
근데 진짜 하루아침에 " 다 내다버리고 sign함수로 해도 되는 거 같은데?는 너무 컸음 이전에 결국 버려졌던 아이디어가 갑자기 무덤 뚫고 그 위에 세워진 건물도 뚫고 날아오른 격이라
(IP보기클릭)220.70.***.***
공정 수는 늘었음 90번 정도 하는데 이전엔 전문가들이 하나하나 검증했다면 이제는 그냥 동네 아줌마들이 슬쩍 봤는데도 결과가 괜찮은데요?가 된 거
(IP보기클릭)119.206.***.***
결론은 왜 되는지는 모르겠는데 되는데용?인거야?
(IP보기클릭)39.117.***.***
그럼 N모시기 회사에는 악재가 되는건가
(IP보기클릭)220.70.***.***
안 차이난다고 주장하고 있음 그래서 지금 나도 궁금해서 llama-2에 위키피디아 구워보는 중임 다른 사람이 정규방식으로 학습시킨 거랑 나란히 놓고 물어볼려고 결과는 회사자원이라 아마 못 올리겠지만
(IP보기클릭)220.70.***.***
근데 데이터의 detail 소실이 어마어마한거거든 480p로 된 도쿄 거리영상 두개면 4k 영상보다 더 선명해요 같은 소리를 들은 느낌임
(IP보기클릭)119.206.***.***
결론은 왜 되는지는 모르겠는데 되는데용?인거야?
(IP보기클릭)223.38.***.***
근데 보통 ai 논문들이 이런식임ㅋㅋ 설명을 갖다 붙이긴 하는데 블랙박스라 100퍼 정확하게는 모름 | 24.03.06 18:40 | | |
(IP보기클릭)114.203.***.***
그니깐 너가 스카이넷 개발자중 하나라는거지?? 암살한다
(IP보기클릭)221.150.***.***
조만간 창업? 회사 이름은 사이버다인? | 24.03.06 21:19 | | |
(IP보기클릭)118.235.***.***
(IP보기클릭)220.70.***.***
클라크 켄트
공정 수는 늘었음 90번 정도 하는데 이전엔 전문가들이 하나하나 검증했다면 이제는 그냥 동네 아줌마들이 슬쩍 봤는데도 결과가 괜찮은데요?가 된 거 | 24.03.06 18:20 | | |
(IP보기클릭)106.102.***.***
전문가 3명이 붙어서해야하는걸, 일용직 6명 붙이니까 되는데용? 이건가... | 24.03.06 18:24 | | |
(IP보기클릭)122.38.***.***
동내 아줌마가 아니고 옆집 애기가 보고 결과가 괜찮은데요 했어야지 | 24.03.06 18:35 | | |
(IP보기클릭)210.113.***.***
클라크 켄트
위에 그림만 봐도 대충 알거 같은데요. 0.04892 -0.02834 **** 0.05888 이랬던게 0 -0 **** 1 이렇게 간단히 해도 결과 값이 같다 이거 같은데요. | 24.03.06 18:44 | | |
삭제된 댓글입니다.
(IP보기클릭)59.11.***.***
nomnom88
지금 발전이 소프트웨어니 WD 말고 써멀 사다놔라 | 24.03.06 18:35 | | |
(IP보기클릭)39.117.***.***
그럼 N모시기 회사에는 악재가 되는건가
(IP보기클릭)118.235.***.***
게틀링건생각하면 악재아닌듯 | 24.03.06 18:19 | | |
(IP보기클릭)122.42.***.***
모르지. gpu가 없어도 될 걸 만약에 gpu까지 왕창 달고 한다면 한계가 어디일지가 무서운거니까 만약 그게 쓸데가 있다면 오히려 더 날아가겠지 | 24.03.06 18:40 | | |
삭제된 댓글입니다.
(IP보기클릭)220.70.***.***
코카콜라x펩시
근데 진짜 하루아침에 " 다 내다버리고 sign함수로 해도 되는 거 같은데?는 너무 컸음 이전에 결국 버려졌던 아이디어가 갑자기 무덤 뚫고 그 위에 세워진 건물도 뚫고 날아오른 격이라 | 24.03.06 18:20 | | |
(IP보기클릭)121.176.***.***
이게 엘든링에 나오는 토푸스의 역장인가 하는 그건가 | 24.03.06 18:28 | | |
(IP보기클릭)219.250.***.***
코카콜라x펩시
지금까진 그게 다 구려서 그럼 그렇지 했늨데 트랜스포머에선 ㄷ힐거같은게? 가 충격적인… | 24.03.06 21:47 | | |
(IP보기클릭)219.250.***.***
코카콜라x펩시
난 아예 양자연산이 들어가면 더 개판ㄴ날거같음.. | 24.03.06 23:41 | | |
(IP보기클릭)114.204.***.***
(IP보기클릭)220.80.***.***
(IP보기클릭)168.131.***.***
(IP보기클릭)220.70.***.***
안 차이난다고 주장하고 있음 그래서 지금 나도 궁금해서 llama-2에 위키피디아 구워보는 중임 다른 사람이 정규방식으로 학습시킨 거랑 나란히 놓고 물어볼려고 결과는 회사자원이라 아마 못 올리겠지만 | 24.03.06 18:21 | | |
(IP보기클릭)168.131.***.***
정말 차이가 안나면 좋겠다고 생각하는게 Ai 생산성이 유의미해져버리면 기업들이 사람들을 고용을 안할텐데 그 유의미한 생산수단이 보편화되면 기업이나 개인이나 생산성은 비슷비슷하니 결국 거기서 거기가 되지 않을까 싶어서 기술이 보편화되는건 환영할 만 하지 | 24.03.06 18:23 | | |
(IP보기클릭)223.62.***.***
(IP보기클릭)223.62.***.***
학습을 완료한 상태에서 가지치기 느낌으로 하는거면 '아 왠만한건 0 1 -1 셋 중 하나 가까이로 가는구나' 할 만 한데 학습 도중에도...? | 24.03.06 18:22 | | |
(IP보기클릭)220.70.***.***
아예 학습을 이걸로 하래..... 이해가 안 가는데 일단 다른 건 몰라도 gpu의 vram 소모율은 수직낙하함 이거 | 24.03.06 18:23 | | |
(IP보기클릭)223.62.***.***
아니 근데 학습은 어케함? 애초에 시그모이드던 ReLU던 뭐던 썼던게 그라디언트 전파 때문 아니었음? 내가 아직 학부생이라서 잘 모를 수도 있긴 한데 | 24.03.06 18:24 | | |
(IP보기클릭)220.70.***.***
일본인 개발자에 따르면 epoch 10 정도 가져간 게 epoch 3 가져간 기존 트랜스포머 학습 기본형이랑 비슷하다고 해서 그대로 변인 따라서 하는 중.... | 24.03.06 18:24 | | |
(IP보기클릭)220.70.***.***
나도 이쪽 전공 대학원생은 아니고 연구에 필요해서 썼었다가 지금은 회사에서 ai 해보래서 덤으로 하는 쪽이거든 https://github.com/Beomi/BitNet-Transformers 여기 이 분 깃헙이랑 논문 원본 읽어보는거 추천함 Straight-Through Estimator기법으로 미분을 대리해서 하는 아이디어임 | 24.03.06 18:27 | | |
(IP보기클릭)220.70.***.***
그레디언트를 미소변화량만 남기고 컷하는 기법이라고 대강 알고 있는데 하여간 그냥 거 왜 이게 됨 수준이라... | 24.03.06 18:29 | | |
(IP보기클릭)223.62.***.***
좀 더 찾아봐야겠다 | 24.03.06 18:31 | | |
(IP보기클릭)114.207.***.***
(IP보기클릭)211.234.***.***
오 이 사람 좀 똑똑한 듯 | 24.03.06 18:25 | | |
(IP보기클릭)59.31.***.***
(IP보기클릭)220.70.***.***
전문가가 하나 열심히 ㅂㅈ 않고 대충 보는 알바생이 두 번 보면 되는데요? 같은 발상임 | 24.03.06 18:22 | | |
(IP보기클릭)118.235.***.***
(IP보기클릭)220.70.***.***
근데 데이터의 detail 소실이 어마어마한거거든 480p로 된 도쿄 거리영상 두개면 4k 영상보다 더 선명해요 같은 소리를 들은 느낌임 | 24.03.06 18:23 | | |
(IP보기클릭)119.192.***.***
(IP보기클릭)221.158.***.***
어 이런 발상이... 컴터가 훨 좋아졌으니 그래픽CG도 만드는데 시간 훨 적게 들어가겠네? ...라고들 생각했지만, 실제로는 그냥 그만큼 퀄리티와 해상도가 증가했지. 작업 시간은 줄어들지 않음... 이것도 마찬가지로 GPU안써도 되는게 아니라, 뭔가 반응속도나 범위 향상 그런걸로 가겠지.
(IP보기클릭)220.70.***.***
vram+ 행렬연산의 속도 이슈 떄문에 gpu 썼는데 이 방식이면 cpu 개량해서 쓰던가 극단적으로 ram 적게 달린 전용 기판 만들어도 대형 gpu랑 동등한 효과가 남 | 24.03.06 18:29 | | |
(IP보기클릭)220.70.***.***
이게 단지 부동소수점 벡터연산을 할 수 있는 기기가 gpu라서 gpu를 쓴 거야 텐서 메인이던 시절엔 tpu 만들어쓰다가, GPU를 아예 연산용으로 개조하는 걸로 바뀌어서 a100 같은 게 나온거고 | 24.03.06 18:30 | | |
(IP보기클릭)220.70.***.***
GPU대신 다른 거(싼 거)를 써도 되겠네?인 거임 원래 4090 4개는 클러스터링해야 할 학습을 (아니면 자체적으로 지연계산시켜야 할 걸) 부분적으로 적용한 코드만으로 1개만으로 되는 시점에서 정신나간거 | 24.03.06 18:31 | | |
(IP보기클릭)119.206.***.***
오늘 엔비디아 주식 얼마나 나락가나 한번 봐야겠다 | 24.03.06 18:52 | | |
(IP보기클릭)118.235.***.***
그래픽 cg의 퀄리티와 해상도가 만족으러운 경지에 도달하면 그 후로는 성능 증가가 시간단축으로 이어지지 않을까? | 24.03.06 22:50 | | |
(IP보기클릭)221.158.***.***
어 그 생각 20년전에도 15년전에도 10년전에도 5년전에도 업계인들은 했었어... 아마 앞으로도 희망사항으로서 생각은 계속 하게 될거야... | 24.03.07 00:18 | | |
(IP보기클릭)223.38.***.***
(IP보기클릭)211.54.***.***
(IP보기클릭)123.248.***.***
(IP보기클릭)86.48.***.***
적당히 큰 수는 부호(sign)만 따지고 적당히 작은 건 전부 0으로 취급 | 24.03.06 18:24 | | |
(IP보기클릭)121.127.***.***
반올림 한다는거 같은데 아닌가? | 24.03.06 18:27 | | |
(IP보기클릭)223.39.***.***
모델을 학습시킬 때, 가중치 행렬에 대해 가중치 행렬 절대값의 평균으로 나눕니다. 그 후 행렬의 각 원소가1, 0, -1 셋 중 가장 가까운 값이 되도록 양자화합니다. | 24.03.06 18:27 | | |
(IP보기클릭)86.48.***.***
첨부된 논문을 보면 알겠지만, 행렬 원소에 절대값을 취한 뒤 전부 더해서 평균을 낸 것을 각 원소에 대해 나누고 RoundClip이라는 지들이 새로 정의한 함수에 넣어서 -1, 0, 1로 변환함 그래서 적당히 큰 것들은 부호만 따지고 적당히 작은 것들은 전부 0 | 24.03.06 18:29 | | |
(IP보기클릭)14.39.***.***
(IP보기클릭)14.52.***.***
ㄴㄴ 오히려 vram 굳이 더 안넣어도 되겠네 로 갈듯 | 24.03.06 18:31 | | |
(IP보기클릭)123.213.***.***
(IP보기클릭)223.62.***.***
(IP보기클릭)220.70.***.***
몰라요. 근데 연구진들은 gpu 말고 다른 걸 처음부터 만들어야 한다고 주장하고 있습니다 | 24.03.06 18:32 | | |
(IP보기클릭)118.34.***.***
(IP보기클릭)220.70.***.***
나도 단지 따라가는 팔로워일 뿐임 연구 아니고 누가 해놓은 거 보고 낑겨넣어서 시도해보는 정도임 | 24.03.06 18:32 | | |
(IP보기클릭)124.137.***.***
(IP보기클릭)183.104.***.***
(IP보기클릭)220.70.***.***
박사 아니에요 거기까지 못가고 취직함 | 24.03.06 18:32 | | |
(IP보기클릭)211.234.***.***
뭐야 무잔 버리고 탈출한 거자나 | 24.03.06 18:42 | | |
(IP보기클릭)183.104.***.***
앗... 혹시나 제 경솔한 댓글로 인하여 기분이 나쁘셨다면 정말 미안합니다. 흥미로운 소식 알기쉽게 잘 풀어서 소개해주셔서 너무 고마워요! | 24.03.06 18:51 | | |
(IP보기클릭)220.70.***.***
아뇨아뇨 근데 언젠가 박사는 따야한다고 생각하고 있음.... 돈벌고 야간 대학원 가야죠 ㅠㅠ | 24.03.06 18:51 | | |
(IP보기클릭)118.235.***.***
(IP보기클릭)220.70.***.***
이해가 안 가죠... 선생님 이거 좀 추가해설 가능하신? 제가 bitnet 기반을 이전에 뭐 이딴 게 다 있어 하고 넘겨서 이해가 부족함 ㅠㅠ | 24.03.06 18:33 | | |
(IP보기클릭)211.225.***.***
(IP보기클릭)211.225.***.***
그래서 아날로그 방식의 연산칩이 AI쪽에서 중요하다라는 논지의 유튜브를 봤었는데.. | 24.03.06 18:27 | | |
(IP보기클릭)223.39.***.***
이게 양자화 연구에 흐름이 있어서 어느 시점을 말씀하시는지 모르겠는데, LLM은 fp16, 16비트 실수를 사용하는 경우가 많았습니다. 이를 더 줄이고 int를 사용하여 int8이나 int4 양자화를 쓰곤 했죠. 이러한 흐름에서 극단적인 양자화, 1bit 가중치만 쓰는 연구(본문의 이전 연구)가 나왔지만 당시 성능은 높지 않았습니다. 따라서 int4 (16개의 값)가 한계처럼 보였습니다. 그런데 이번에 1.58bit (3개의 값)으로 fp16 수준의 성능을 낼 수있다고 주장하는 논문이 나온 겁니다. 또한 이게 유의미한 또 다른 이유는, 양자화의 의의에 있습니다. 기존에는 양자화를 모델 압축에만 쓰는 경우가 있었습니다. 이 경우 자주 사용되는 fp16 값 16개 (int4 기준)를 사전으로 만들어두고, 모델을 사용할 때 그 사전을 참고하여 연산을 하는 것이라고 보면됩니다. 즉 저장공간은 줄지만 여전히 float 곱셈과 덧셈 연산이 필요하죠. 하지만 저 논문의 주장이 사실이라면, 1.58bit를 가지고 연산 할 때 곱셈은 필요 없습니다. 식이 덧셈과 뺄셈만으로 표현 가능해지니까요. 즉 연산 비용도 획기적으로 줄일 수 있는 것입니다. | 24.03.06 18:35 | | |
(IP보기클릭)220.70.***.***
네 선형대수적으로 0,1,-1로만 된 행렬연산은 복수 개가 곱해져도 단일행렬로 합칠 수가 있으니까요.... | 24.03.06 18:38 | | |
(IP보기클릭)211.225.***.***
제가 본문을 대충봤나보네요 단순 소숫점 컷해서 성능올리는 이야기인줄 알았는데 1 0 -1 이정도로 극단적인 반올림으로 기존과 유사한 성능이 나온다는게 대단한 거군요 | 24.03.06 18:42 | | |
(IP보기클릭)156.146.***.***
(IP보기클릭)118.35.***.***
(IP보기클릭)223.38.***.***
(IP보기클릭)220.70.***.***
루리웹-1083374988
근데 연산 컷량이 어마어마해요 | 24.03.06 18:34 | | |
(IP보기클릭)113.198.***.***
(IP보기클릭)59.29.***.***
(IP보기클릭)172.226.***.***
(IP보기클릭)118.235.***.***
(IP보기클릭)220.87.***.***
(IP보기클릭)211.234.***.***
(IP보기클릭)119.149.***.***
(IP보기클릭)220.70.***.***
제가 저 이론을 몰라서 그냥 저도 해본다 추라이로 들이박는거라.... 애초에 데이터를 양자화시켜서 계산하는 거면 계산논문 난이도가 정신나간단 말이죠 학부 때 디지털신호 아날로그화할 떄의 공포가 다시 돌아온다..... | 24.03.06 18:35 | | |
삭제된 댓글입니다.
(IP보기클릭)221.141.***.***
루리웹-6878455132
ai논문요약 by 챗지피티 | 24.03.06 18:37 | | |
(IP보기클릭)211.33.***.***
(IP보기클릭)211.33.***.***
만약 이게 된다면 공학처럼 유효숫자화 해서 그냥 유효숫자 단 세개만으로 연산하고 심화연산 필요한 것만 남겨두면 그만 아닌가? 싶네 어차피 미소값은 남겨둘수록 계산만 더러워지고, 실제로 계산에서 차지하는 양은 미미할테니 | 24.03.06 19:01 | | |
(IP보기클릭)211.234.***.***
(IP보기클릭)220.70.***.***
저거에 최적화된 새 기판도 엔비디아가 만들지도모름 | 24.03.06 18:35 | | |
(IP보기클릭)211.234.***.***
필요 절대량 자체가 줄기 때문에 매출하락은 피할 수 없음 | 24.03.06 18:36 | | |
(IP보기클릭)220.70.***.***
저게 사실이면 진짜 아무데나 쑤셔박아도 될 거라서 기판의 총생산량은 늘 거라 엔비디아 주식 절반 팔고 나머지는 삼성이나 tmdc 사야지 | 24.03.06 18:39 | | |
(IP보기클릭)59.11.***.***
(IP보기클릭)117.111.***.***
(IP보기클릭)119.64.***.***
(IP보기클릭)211.38.***.***
(IP보기클릭)211.38.***.***
(IP보기클릭)58.29.***.***
(IP보기클릭)211.33.***.***
(IP보기클릭)220.70.***.***
아냐 그건 안돼 행렬연산을 줄이는 것도 많긴 한데 아직 한계가 많음 보이는 거 계산을 줄이면 말그대로 해상도가 내려간 것과 같은 결과가 나와요 | 24.03.06 18:45 | | |
(IP보기클릭)211.33.***.***
이 방법으로 경향성과 방향성만 잡을 수 있는거구나? 그러면 정확한 값을 요구하는데는 아직 무리인거고 | 24.03.06 18:48 | | |
(IP보기클릭)121.183.***.***