
삼성의 엑시노스 2600은 SME2를 지원하며(CPU는 C1-Ultra와 C1-Pro의 조합임), 특정 AI 애플리케이션에서 최대 70%의 성능 향상이 있다고 합니다.
Exynos 2600과 SME2의 조합은 AI 성능을 70% 향상시켜 게임과 사진 촬영을 더욱 부드럽게 만들어 줌
C1-Ultra와 C1-Pro의 조합은 성능과 에너지 효율의 균형을 완벽하게 맞춰줌

Landsknecht™
(66332)
유저정보 정보통 추천흡수기
출석일수 : 7170일 LV.127
Exp.50%
추천 7 조회 1842 비추력 5870
작성일 2026.02.12 (18:03:40)
IP : (IP보기클릭)211.235.***.***
삼성의 엑시노스 2600은 SME2를 지원하며(CPU는 C1-Ultra와 C1-Pro의 조합임), 특정 AI 애플리케이션에서 최대 70%의 성능 향상이 있다고 합니다.
Exynos 2600과 SME2의 조합은 AI 성능을 70% 향상시켜 게임과 사진 촬영을 더욱 부드럽게 만들어 줌
C1-Ultra와 C1-Pro의 조합은 성능과 에너지 효율의 균형을 완벽하게 맞춰줌
(IP보기클릭)211.235.***.***
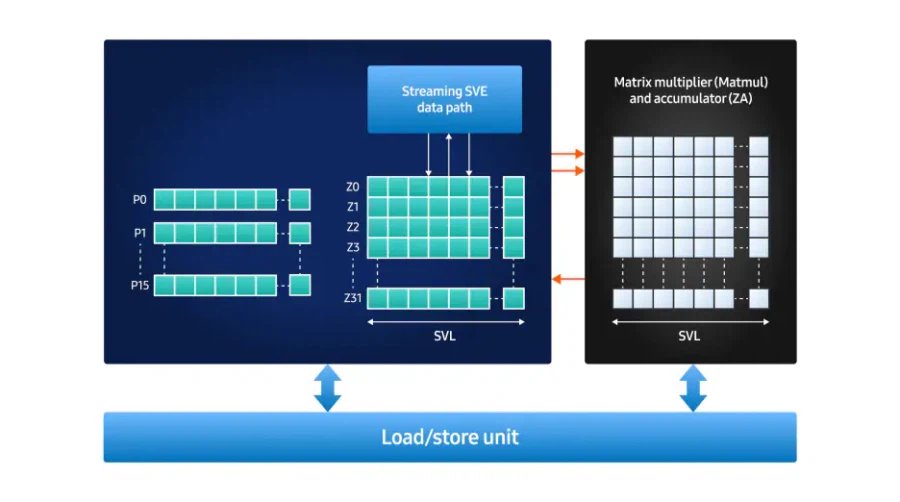
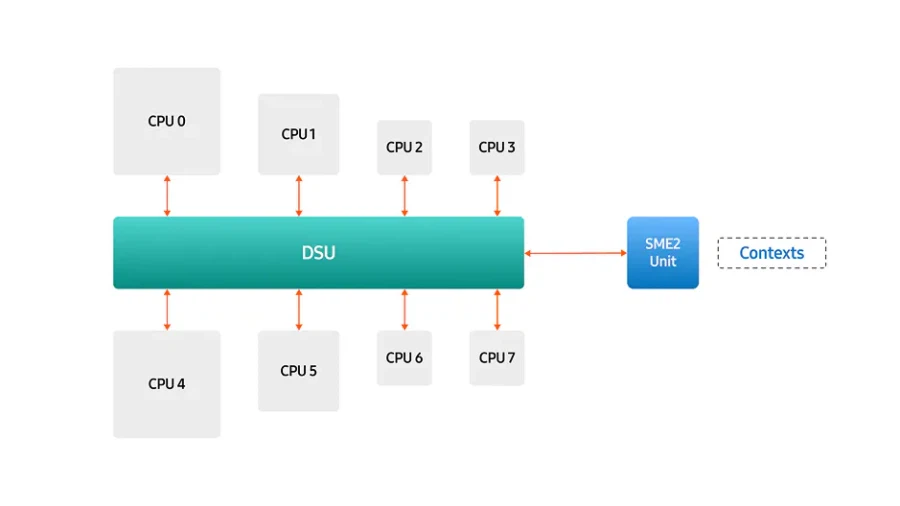
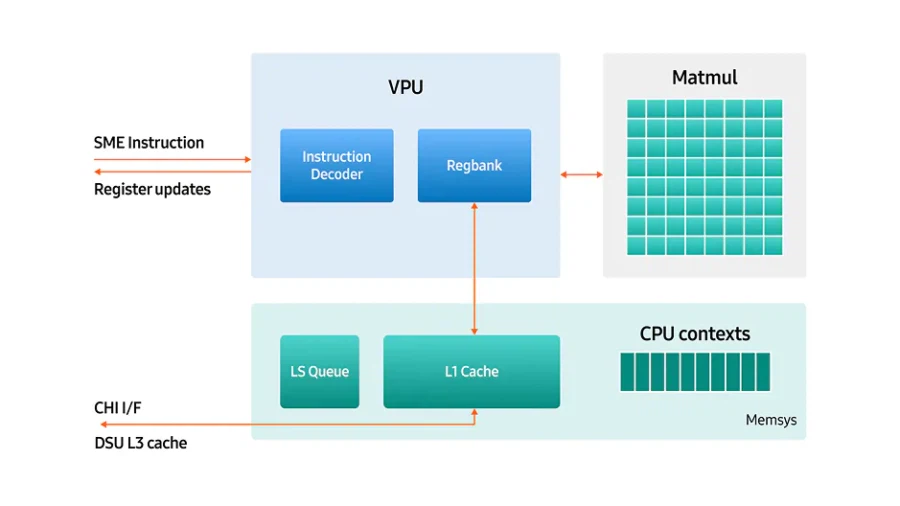
SME2 지원 의미 기존 CPU 아키텍처는 머신러닝 연산에서 요구되는 대규모 병렬 연산을 효율적으로 처리하기에는 구조적인 한계를 지님 이러한 한계를 보완하기 위해 제안된 기술이 SME2(Scalable Matrix Extension 2) SME2는 기존 모바일 CPU의 Arm 명령어 집합에 포함된 확장 ISA¹로, 행렬 연산을 효과적으로 가속할 수 있도록 설계 이를 통해 CPU가 지닌 프로그래밍 유연성을 유지하면서도, 온디바이스 AI에 필요한 연산 성능을 확보할 수 있는 기반이 마련
(IP보기클릭)147.47.***.***
Tensor Core 같은 행렬곱 연산기입니다. 차이점은 systolic array가 아니라 Vector x Vector의 Outer Product 형태로 구성된 유닛이라서 기존 SVE 연산 가속에도 활용가능하다고 합니다.
(IP보기클릭)211.235.***.***
(IP보기클릭)1.237.***.***
(IP보기클릭)14.42.***.***
ai 관련 연산이 cpu 안에서 도니까 지연시간 측면에서도 유리하고, npu 대비 개발환경도 훨씬 범용적일테니. | 26.02.12 19:10 | | |
(IP보기클릭)118.235.***.***
어차피 요즘 ai 연산이 gpu에 통합해서 행렬연산이랑 gpu의 int와 fp병렬자원을 동시에 하는쪽으로 가고 있어서 cpu는 애진작 api실행시켜주는 터미널 역할 수준으로밖에 안쓰거든요. 그래서 그런거죠. | 26.02.12 19:44 | | |
(IP보기클릭)14.42.***.***
대규모 언어모델이면 모를까, 스마트폰이나 PC 수준의 폼팩터에선 절대성능보단 최대한 적은 지연시간과 오버헤드로 즉각적으로 처리해야 하는 경우들이 있으니까요. 그래서 NPU따로 GPU따로 CPU따로 해서 계속 AI연산에 맞게 발전해가고 있는 거. | 26.02.12 19:48 | | |
(IP보기클릭)147.47.***.***
Tensor Core 같은 행렬곱 연산기입니다. 차이점은 systolic array가 아니라 Vector x Vector의 Outer Product 형태로 구성된 유닛이라서 기존 SVE 연산 가속에도 활용가능하다고 합니다.